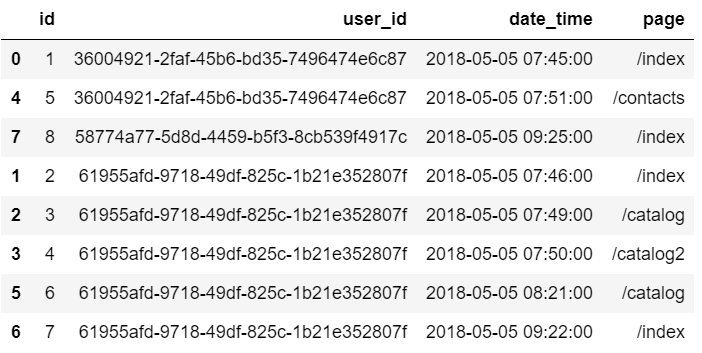
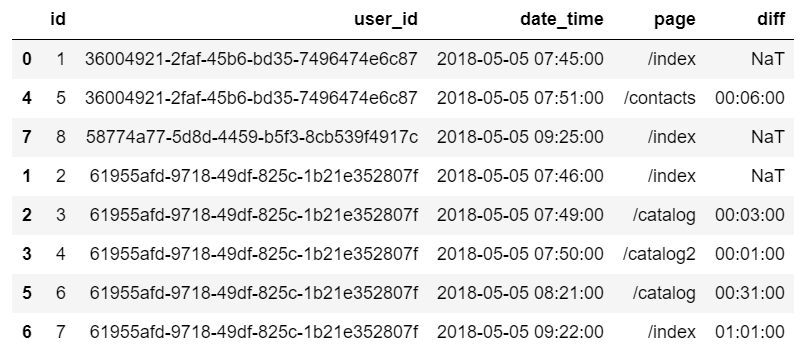
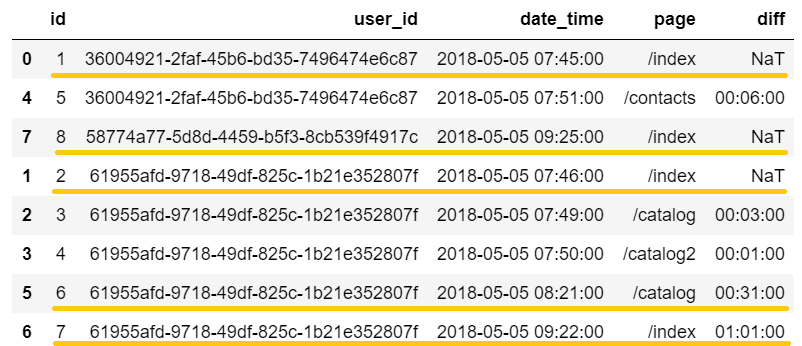
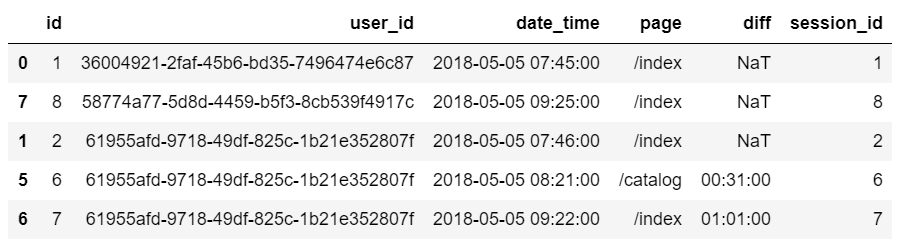
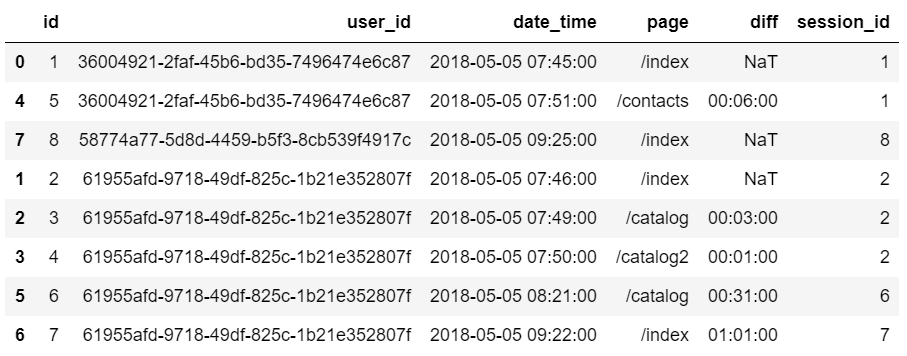
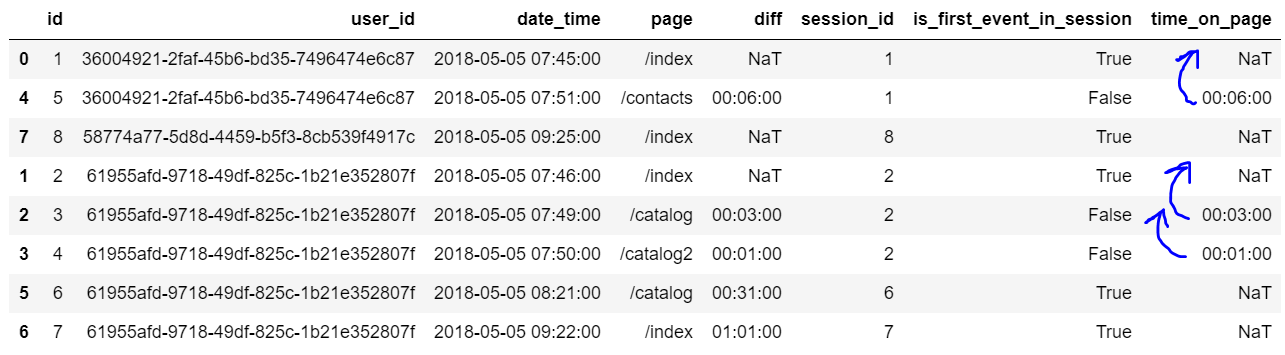
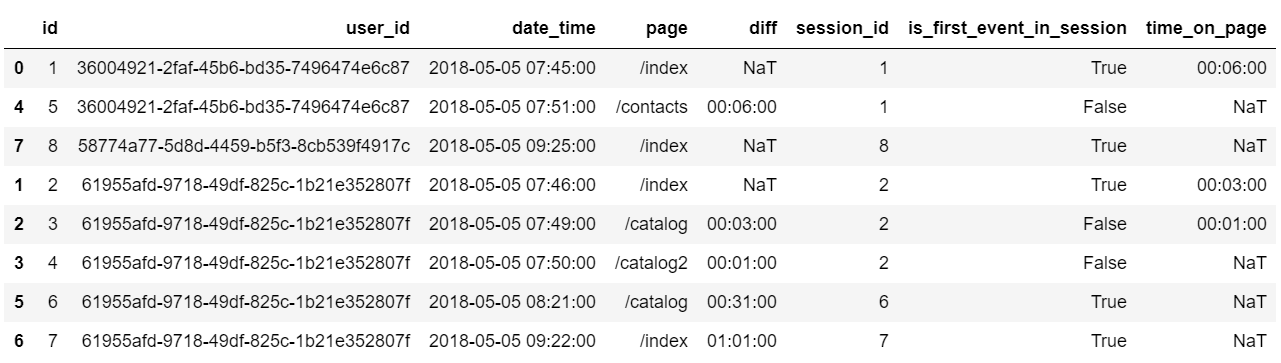
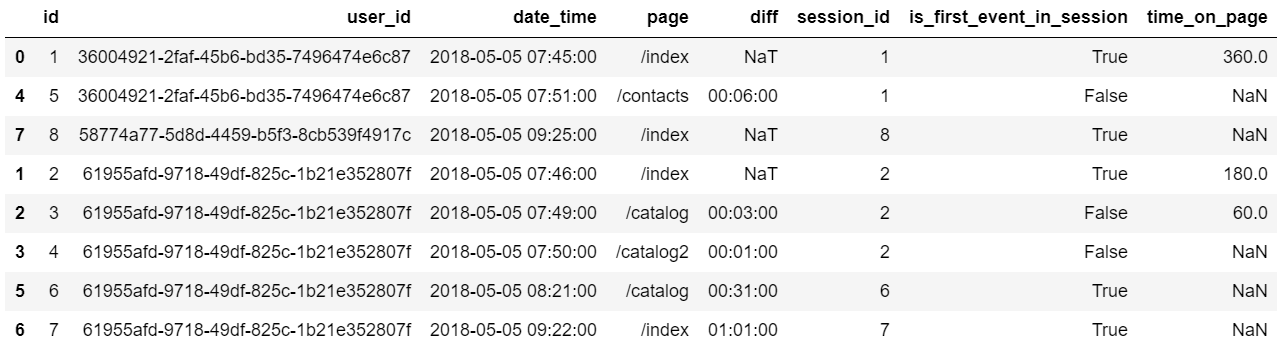
Углубленное изучение Pandas: структуры данных
Есть у меня определенное мнение, что понимание базовых структур данных в Pandas крайне важно, потому что это дает нам представление о фундаментальной основе тех операций, которые мы выполняем с данными. Pandas очень прост и предоставляет простой способ организации данных и манипулирования ими. Но часто бывает так, что для того, чтобы сделать что-то, выходящее за рамки мануалов из сети, мы должны сначала понять основные принципы, на которых построена технология. Структуры данных Series и DataFrame — это строительные блоки, из которых построена работа с данными в Pandas. И их понимание может помочь нам лучаше понять Pandas как продвинутый инструмент. Благодаря лучшему пониманию структур данных нам будет легче создавать эффективные пайплайны обработки данных, легче читать и поддерживать код, делать его более переиспользуемым. В конечном счете, понимая как Pandas работает на более глубоком уровне, позволит раскрыть потенциал Pandas на полную.
Это первая статья из серии статей про углубленное изучение Pandas. В ней поговорим про основные структуры данных.
Введение
Pandas — одна из наиболее важных и широко используемых библиотек анализа данных в Python. Чтобы эффективно использовать Pandas, важно понимать две основные структуры данных, которые он предлагает: Series и DataFrame.
Series и DataFrames являются важными структурами данных, которые используются для хранения, обработки и анализа данных в Pandas. В этом уроке мы дадим всестороннее представление об этих структурах данных, включая их создание и индексация внутри этих структур данных. Также поделимся особенностями работы этих структур.
Этот пост будет посвящен следующим темам:
- Объяснение разницы между Series и DataFrame;
- Объяснение структуры данных Series в Pandas;
- Обсуждение разницы между списком и Series;
- Обсуждение того, как библиотека Pandas автоматически присваивает тип данных элементам в серии;
- Объяснение структуры и свойств DataFrame, включая его столбцы, индекс и взаимосвязь между столбцами и строками как объектами Series.
II. Разница между Series и DataFrame
Представьте, что у вас есть последовательность точек данных, представляющих одну переменную, такую как рост, вес или возраст. Эта последовательность (мы её ещё можем назвать серией точек) точек данных может быть представлена с помощью объекта Series в Pandas. Series (можно перевести как «ряд») — это одномерная структура данных, которая содержит последовательность значений и похожа на список или массив.
Вот пример Series:
0 78
1 53
2 76
3 67
4 60
Name: age, dtype: int64
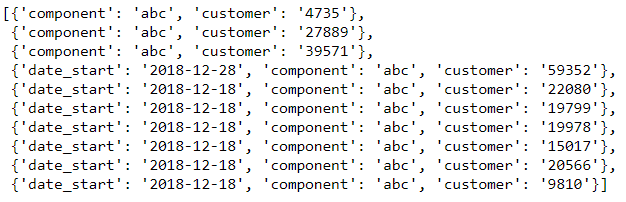
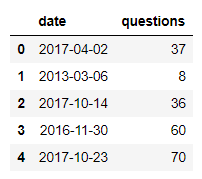
Теперь представьте, что у вас есть сетка точек данных, представляющих множество переменных, таких как рост, вес, возраст и город для нескольких человек. Эта сетка точек данных может быть представлена с помощью DataFrame в Pandas. DataFrame — это двумерная структура данных, которая содержит несколько столбцов данных, каждый из которых имеет разное имя переменной.
.png)
Вот пример DataFrame:
height weight age
0 187.640523 83.831507 78
1 174.001572 51.522409 53
2 179.787380 52.295150 76
3 192.408932 74.693967 67
4 188.675580 53.268766 60
Разницу между Series и DataFrame можно сравнить с разницей между линией и квадратом. Линия является одномерной и может содержать только одну последовательность точек данных, в то время как квадрат является двумерным и может содержать несколько последовательностей точек. Таким же образом, Series содержит одну последовательность точек данных, в то время как DataFrame содержит несколько последовательностей точек данных в разных столбцах.
Итак, при работе с данными в Pandas важно понимать разницу между Series и DataFrame и выбирать соответствующую структуру данных на основе размерности ваших данных.
III. Структура данных Series
Series — это одномерный индексированный массив, способный содержать любой тип данных.
Создать Series в Pandas довольно просто. Чтобы создать Series, вы просто передаете список значений в виде списка в функцию `pd.Series()` и при желании указываете индекс. Вот пример:
import pandas as pd
import numpy as np
s = pd.Series([1, 3, 5, np.nan, 6, 8])
print(s)
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
А вот пример создания Series с указанием индекса:
s = pd.Series([1, 3, 5, np.nan, 6, 8], index = [1,2,3,5,8,11])
print(s)
1 1.0
2 3.0
3 5.0
5 NaN
8 6.0
11 8.0
dtype: float64
Автоматическое определение типов
Когда вы передаете список в объект Series, Pandas автоматически определяет тип данных элементов в списке и присваивает серии соответствующий тип данных. Это означает, что вам не нужно вручную указывать тип данных, и Pandas позаботится об этом за вас.
Например, если вы передадите список целых чисел объекту Series, Pandas автоматически присвоит серии тип данных integer. Если вы передадите список строк, Pandas присвоит серии строковый тип данных. Это делает работу с данными в Pandas удобной и легкой, так как вам не нужно беспокоиться о ручном указании типа данных для каждой серии.
Вот пример, иллюстрирующий эту мысль:
# Создаем Series из списка целых чисел
integer_series = pd.Series([1, 2, 3, 4, 5])
print("Data type of integer series:", integer_series.dtype)
# Создаем Series из списка строк
string_series = pd.Series(["apple", "banana", "cherry", "date"])
print("Data type of string series:", string_series.dtype)
Data type of integer series: int64
Data type of string series: object
Как вы можете видеть, Pandas автоматически определил тип данных элементов в списке и присвоил Series соответствующий тип данных. В первом случае список целых чисел передается объекту Series, поэтому Pandas присваивает серии целочисленный тип данных `int64`. Во втором случае список строк передается объекту Series, поэтому Pandas присваивает Series тип данных `object`, поскольку строки хранятся в Pandas как объекты.
Автоматическое определение типов при смешанных типах
Если в списке есть хотя бы один элемент с типом данных `str`, то Pandas присвоит объектный тип данных всей серии, независимо от типов данных других элементов в списке.
Вот пример, иллюстрирующий это:
# Создаем Series, содержащий как целые числа, так и строки
mixed_series = pd.Series([1, 2, "apple", 4, "banana"])
print("Data type of mixed series:", mixed_series.dtype)
Data type of mixed series: object
Как вы можете видеть, несмотря на то, что список, переданный конструктору pd.Series(), содержит как целые числа, так и строки, результирующий Series имеет тип данных `object`, поскольку в списке есть по крайней мере один элемент с типом данных `str`. Это означает, что все элементы в Series будут рассматриваться как объекты, независимо от их фактического типа данных.
Индексирование в Series
Индексирование и построение срезов (slicing) в Series работают аналогично индексации в списке или массиве. Вы можете получить доступ к отдельным элементам серии, используя квадратные скобки со значением индекса. Вот пример:
print(s[0])
1.0
print(s[:3])
0 1.0
1 3.0
2 5.0
dtype: float64
Атрибут index
Вызов атрибута `index` в Series позволяет получить объект, который содержит индексы для каждого элемента в серии. Вы можете использовать атрибут index для извлечения индексов для каждого элемента в Series и выполнения над ними различных операций.
Вот несколько примеров того, как использовать атрибут index в Series:
# Создание Series со стандартными индексами
default_index_series = pd.Series([1, 2, 3, 4, 5])
# Вызов индексов
print(default_index_series.index)
RangeIndex(start=0, stop=5, step=1)
# Создание Series с пользовательскими индексами
custom_index_series = pd.Series([1, 2, 3, 4, 5], index=["a", "b", "c", "d", "e"])
# Вызов индексов
print(custom_index_series.index)
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
# Изменение индексов
custom_index_series.index = ["x", "y", "z", "w", "v"]
print(custom_index_series)
x 1
y 2
z 3
w 4
v 5
dtype: int64
Как вы можете видеть, вы можете получить атрибут `index` из Series, просто вызвав `series.index`. Кроме того, вы можете изменить атрибут `index`, присвоив ему новое значение, как показано в примере выше. Это может быть полезно, когда вы хотите изменить метки для элементов в Series.
Разница и сходство Series и списков
Series и обычные списки в Python похожи: они одномерные, хранят элементы, у элементов есть индексы. Но в отличие от обычного списка, индексы в Series могут быть изменяемыми и не обязательно начинаться с нуля или располагаться в возрастающем порядке. Кроме того, индексы в серии Pandas могут быть как целыми числами, так и строками.
Вот пример, иллюстрирующий это:
# Создаем серию с кастомным индексом
custom_index_series = pd.Series([1, 2, 3, 4, 5], index=["a", "b", "c", "d", "e"])
print(custom_index_series)
# Создаем серию с неинкрементальным индексом
non_incremental_index_series = pd.Series([1, 2, 3, 4, 5], index=[1, 5, 2, 6, 3])
print(non_incremental_index_series)
a 1
b 2
c 3
d 4
e 5
dtype: int64
1 1
5 2
2 3
6 4
3 5
dtype: int64
Как вы можете видеть, в первом примере показан Series с пользовательским индексом, который состоит из строк. Во втором примере показан ряд с неинкрементным индексом, который состоит из целых чисел. Это демонстрирует, что индексы в Series не обязательно должны начинаться с нуля или располагаться в порядке возрастания.
Вы также можете использовать вместе с Series различные методы Pandas, такие как `.head()`, `.tail()`, `.describe()` и т. д. Вот пример:
print(s.head())
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
dtype: float64
print(s.describe())
count 5.000000
mean 4.600000
std 2.701851
min 1.000000
25% 3.000000
50% 5.000000
75% 6.000000
max 8.000000
dtype: float64
Существует множество операций и методов, доступных для Series, таких как арифметические операции, операции сравнения и многое другое. Вы можете использовать их для выполнения различных манипуляций с данными и вычислений.
IV. Структура данных DataFrame
DataFrame (датафрейм) — это двумерная структура данных, которая может содержать несколько типов данных в разных столбцах. Другими словами, DataFrame — это, по сути, таблица со строками и столбцами.
Создание DataFrame в Pandas выполняется с помощью конструктора `pd.DataFrame()`. Вы можете создать DataFrame из списка, словаря или массива NumPy. Вот пример использования словаря для создания DataFrame:
import pandas as pd
data = {
'Name': ['John', 'Jane', 'Jim', 'Joan'],
'Age': [32, 28, 41, 37],
'City': ['New York', 'London', 'Paris', 'Berlin']
}
df = pd.DataFrame(data)
print(df)
Name Age City
0 John 32 New York
1 Jane 28 London
2 Jim 41 Paris
3 Joan 37 Berlin
А вот пример создания DataFrame из списка списков:
# Создаем список списков
data = [['John', 25, 70, 180],
['Jane', 30, 65, 170],
['Jim', 35, 72, 185]]
# Создаем датафрейм из списка списков с колонками 'Name', 'Age', 'Weight', 'Height'
df = pd.DataFrame(data, columns=['Name', 'Age', 'Weight', 'Height'])
Этот код создает список списков под названием data. Каждый список внутри data представляет собой строку в DataFrame и содержит данные об имени, возрасте, весе и росте человека.
Затем мы создаем DataFrame из списка списков, передавая данные конструктору DataFrame. Мы также предоставляем список имен столбцов с аргументом columns.
Результирующий DataFrame будет выглядеть следующим образом:
Name Age Weight Height
0 John 25 70 180
1 Jane 30 65 170
2 Jim 35 72 185
Индексирование и срезы в DataFrame работают аналогично тому, как и в Series. Вы можете получить доступ к отдельным элементам, строкам или столбцам, используя квадратные скобки со значениями индекса. Вот пример:
print(df['Name'])
0 John
1 Jane
2 Jim
Name: Name, dtype: object
print(df[0:2])
Name Age Weight Height
0 John 25 70 180
1 Jane 30 65 170
Колонки — это Series
Когда вы вызываете колонки DataFrame, вы фактически получаете доступ к отдельным объектам Series, по одному для каждой колонки. Индекс внутри каждой Series совпадает с индексом DataFrame, что означает, что он содержит индексы строк внутри DataFrame.
Вот пример, иллюстрирующий это:
import pandas as pd
# Создаем DataFrame
df = pd.DataFrame({"A": [1, 2, 3, 4, 5],
"B": [6, 7, 8, 9, 10]})
# Получаем колонки
col_a = df["A"]
col_b = df["B"]
# Получаем индексы Series (колонок)
print(col_a.index)
print(col_b.index)
# Сравниваем индексы между собой
print(col_a.index == df.index)
print(col_b.index == df.index)
RangeIndex(start=0, stop=5, step=1)
RangeIndex(start=0, stop=5, step=1)
[ True True True True True]
[ True True True True True]
Как вы можете видеть, индекс как `col_a`, так и `col_b` совпадает с индексом DataFrame `df`, и сравнение между ними возвращает массив истинных значений, указывающий на то, что они действительно равны. Это означает, что вы можете использовать индекс DataFrame для доступа и манипулирования значениями в отдельных колонках, а также DataFrame в целом.
Атрибут name у Series
Атрибут `name` у Series позволяет получить название, присвоенное Series. Название используется для идентификации Series и может быть использовано как справочные данные, когда мы работаем с одинарной Series. В случае Series, полученного из DataFrame через доступ к его столбцам, значение атрибута `name` соответствует имени столбца, из которого был получен ряд.
np.random.seed(0)
data = {'height': np.random.normal(170, 10, 100),
'weight': np.random.normal(65, 10, 100),
'age': np.random.randint(18, 80, 100)}
df = pd.DataFrame(data)
height_series = df['height']
print(height_series.name)
height
Этот код выведет «height». «height» — название столбца исходного DataFrame, из которого была получена Series.
Строки — тоже Series
Когда вы извлекаете строку из DataFrame, вы тоже получаете объект Series. Индекс Series в этом случае выступает в качестве метки для каждого элемента в Series, что позволяет получать нужные данные. А ещё индекс Series эквивалентен именам колонок в DataFrame.
import pandas as pd
import numpy as np
np.random.seed(0)
data = {'height': np.random.normal(170, 10, 100),
'weight': np.random.normal(65, 10, 100),
'age': np.random.randint(18, 80, 100)}
df = pd.DataFrame(data)
first_row = df.loc[0]
print(first_row.index)
print(first_row['height'])
Index(['height', 'weight', 'age'], dtype='object')
187.64052345967664
Этот код выведет: Index([’height’, ’weight’, ’age’], dtype=’object’). Сначала мы получили первую строку из DataFrame (df.loc[0]) в виде Series. А затем вывели индекс этого Series. Видно, что он совпадает с именами колонок в DataFrame.
Когда вы извлекаете строку из DataFrame, вы получаете Series, и индекс серии действует как метка для каждого элемента в Series, позволяя вам ссылаться на данные при необходимости (например, таким образом выведено отдельное значение из first_row — first_row[’height’]). В этом случае индекс ряда эквивалентен именам столбцов в DataFrame.
Транспонирование
Сходство между строками и колонками в DataFrame приводит нас к операции транспонирования.
Транспонирование DataFrame — это процесс замены строк и столбцов фрейма данных так, чтобы колонки становились индексом, старый индекс становился названием колонок, а значения строк — значениями колонок. Операция транспонирования может быть сделана с помощью атрибута `T`
.png)
На уровне соединения столбцов и строк DataFrame состоит из нескольких Series, где каждый столбец представляет Series, а индекс каждой Series представляет индексы строк. Транспонирование DataFrame означает, что каждая Series-колонка становится новой строкой в транспонированном DataFrame, а метки строк каждой Series становятся новым индексом для транспонированного DataFrame.
Например, рассмотрим следующий код:
np.random.seed(0)
data = {'height': np.random.normal(170, 10, 100),
'weight': np.random.normal(65, 10, 100),
'age': np.random.randint(18, 80, 100)}
df = pd.DataFrame(data)
transposed_df = df.T
print(transposed_df)
0 1 2 3 4 5 \
height 187.640523 174.001572 179.78738 192.408932 188.675580 160.227221
weight 83.831507 51.522409 52.29515 74.693967 53.268766 84.436212
age 78.000000 53.000000 76.00000 67.000000 60.000000 27.000000
6 7 8 9 ... 90 \
height 179.500884 168.486428 168.967811 174.105985 ... 165.968231
weight 60.863810 57.525452 84.229420 79.805148 ... 52.071431
age 62.000000 31.000000 75.000000 24.000000 ... 27.000000
91 92 93 94 95 \
height 182.224451 172.082750 179.766390 173.563664 177.065732
weight 67.670509 64.607172 53.319065 70.232767 63.284537
age 78.000000 45.000000 65.000000 53.000000 37.000000
96 97 98 99
height 170.105000 187.858705 171.269121 174.019894
weight 72.717906 73.235042 86.632359 78.365279
age 30.000000 36.000000 67.000000 28.000000
[3 rows x 100 columns]
Этот код выведет транспонированный DataFrame, где каждая колонка исходного фрейма данных теперь является строкой в транспонированном DataFrame. Индекс каждой строки в транспонированном DataFrame совпадает с названием столбца в исходном DataFrame, а значения в каждой строке являются значениями из соответствующей колонки в исходном DataFrame.
V. Заключение
Библиотека Pandas для Python предоставляет эффективные структуры данных для хранения данных и манипулирования ими. Структуры Series и DataFrame являются основными объектами в Pandas. Series — это одномерный индексированный массив, а DataFrame — это двумерная структура данных с индексированными строками и столбцами.
DataFrame создаются из объектов Series, и каждая колонка в DataFrame представляет собой Series со своей собственной меткой. Таким же образом, когда мы обращаемся к строке в DataFrame, мы получаем объект Series, и индекс внутри этого объекта совпадает с индексом всего DataFrame.
Важно глубоко понимать, как работают структуры данных Series и DataFrame в Pandas, поскольку они формируют основу всех операций анализа данных в Pandas. Понимание основных свойств, таких как индекс и тип данных, имеет важное значение для эффективного использования Pandas для задач анализа данных. Понимание взаимосвязи между Series и DataFrame помогает лучше обрабатывать данные и манипулировать ими. Знание основополагающих принципов и операций с базовыми структурами данными в Pandas приводит к более эффективному использованию библиотеки при решении реальных проблем с данными.