
Делаем сессии из лога событий с помощью Pandas
Предыстория
Волею судеб передо мной встала необходимость разбить большущий лог событий на сессии. Не буду приводить полный лог, а покажу упрощенный пример:
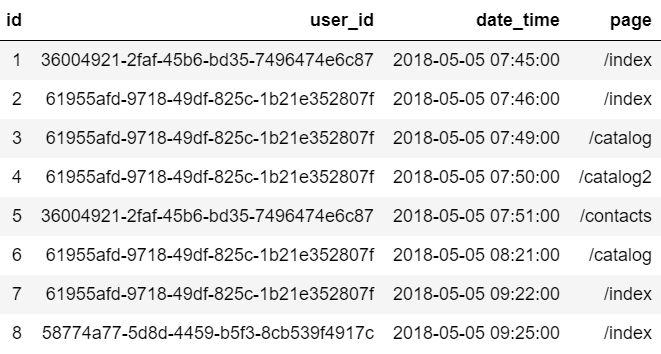
Структура данных лога представляет собой:
- id — порядковый номер события в логе
- user_id — уникальный идентификатор пользователя, совершившего событие (при решении реальной задачи анализа лога в качестве user_id может выступать IP-адрес пользователя или, например, уникальный идентификатор cookie-файла)
- date_time — время совершения события
- page — страница, на которую перешел пользователь (для решения задачи эта колонка не несет никакой пользы, я привожу её для наглядности)
Задача состоит в том, чтобы разбить последовательность событий (просмотров страниц) на вот такие блоки, которые будут сессиями:
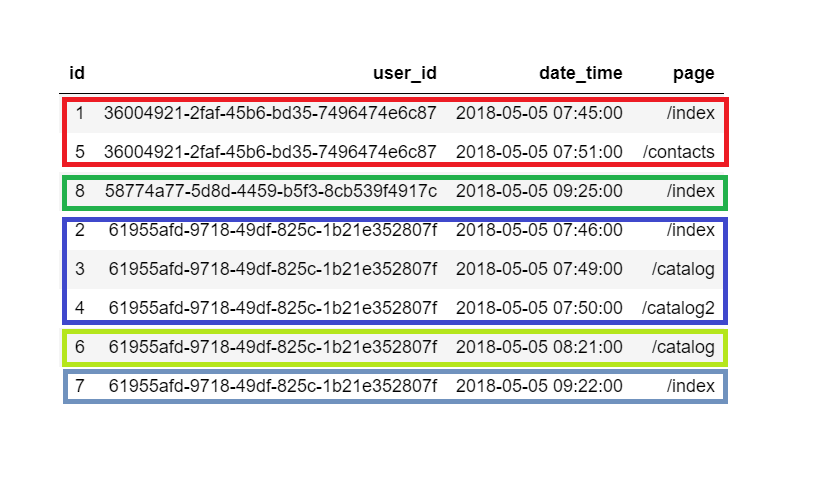
Говоря «разбить», я не имею в виду разделить и сохранить в виде разных массивов данных или ещё что-то подобное. Тут речь идёт о том, чтобы каждому событию сопоставить номер сессии, в которую это событие входит.
Критерий сессии в моем случае — она живет полчаса после предыдущего совершенного события. Например, в строке 6 пользователь перешел на страницу /catalog в 8:21, а следующую страницу /index (строка 7) посмотрел в 9:22. Разница между просмотром страниц составляет 1 час 1 минуту, а значит эти просмотры относятся к разным сессиям этого пользователя.
Все это дело я буду делать на Питоне при помощи Pandas в Jupyter Notebook. Вот ссылка на ноутбук.
Алгоритм
Итак, у нас есть ’event_df’ — это датафрейм, в котором содержатся данные о событиях в привязке к пользователям:
1 События сгенерированные разными пользователями идут в хронологическом порядке. Для удобства отсортируем их по user_id, тогда события каждого пользователя будут идти последовательно:
event_df = event_df.sort_values('user_id')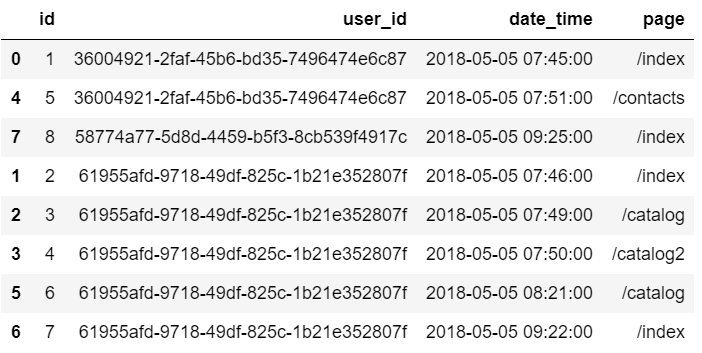
2 В колонке ’diff’ для каждого события отдельного пользователя посчитаем разницу между временем посещения страницы и временем посещения предыдущей страницы. Если страница была первой для пользователя, то значение в колонке ’diff’ будет NaT, т. к. нет предыдущего значения
Обратите внимание, что совместно с функцией diff я использую для группировки пользователей groupby, чтобы считать разницу между временными метками отдельных пользователей. Без использования groupby мы бы просто брали все временные метки и считали бы между ними разницу, что было бы неправильно, так как события относятся к разным пользователям.
event_df['diff'] = event_df.groupby('user_id')['date_time'].diff(1)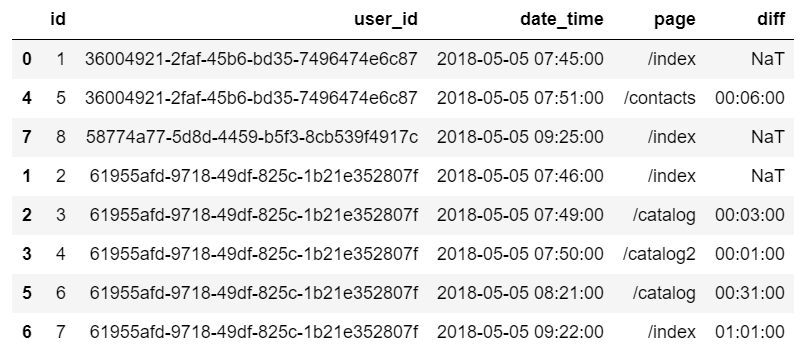
Кое-что уже проклевывается. Мы нашли такие события, которые будут начальными точками для сессий:
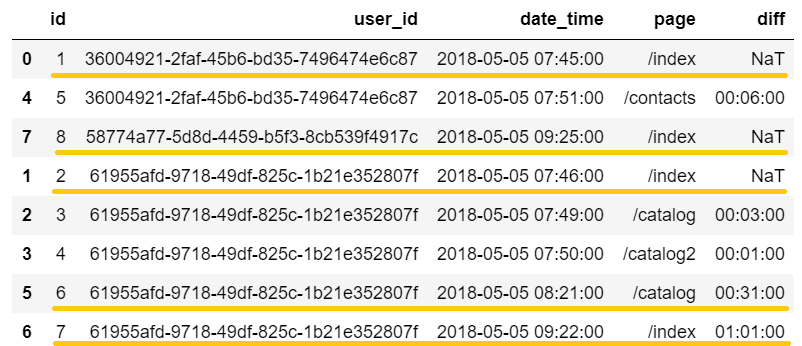
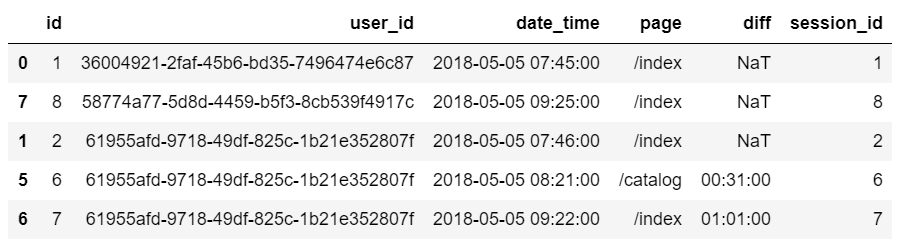
3 Из основного датафрейма ’event_df’ создадим вспомогательный датафрейм ’session_start_df’. Этот датафрейм будет содержать события, которые будут считаться первыми событиями сессий. К таким событиям относятся все события, которые произошли спустя более чем 30 минут после предыдущего, либо события, которые были первыми для пользователя (NaT в колонке ’diff’).
Также создадим во вспомогательном датафрейме колонку ’session_id’, которая будет содержать в себе id первого события сессии. Она пригодится, чтобы корректно отобразить идентификатор сессии, когда будем объединять данные из основного и вспомогательного датафреймов.
sessions_start_df = event_df[(event_df['diff'].isnull()) | (event_df['diff'] > '1800 seconds')]
sessions_start_df['session_id'] = sessions_start_df['id']Вспомогательный датафрейм ’session_start_df’ выглядит так:
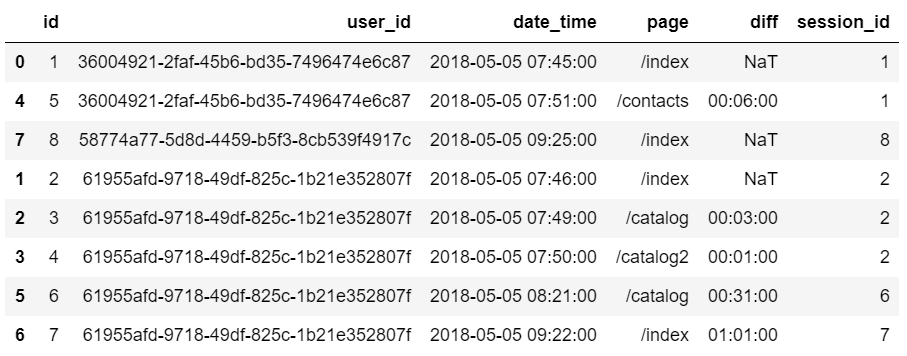
4 С помощью функции merge_asof объединим между собой данные основного и вспомогательного датафреймов. Эта функция позволяет объединить данные двух датафреймов схожим образом с левым join’ом, но не по точному соответствию ключей, а по ближайшему. Примеры и подробности в документации.
Для корректной работы функции merge_asof оба датафрейма должны быть отсортированы по ключу, на основе которого будет происходить объединение. В нашем случае это колонка ’id’.
Обратите внимание, что из датафрейма ’session_start_df’ я выбираю только колонки ’id’, ’user_id’ и ’session_id’, так как остальные колонки особо не нужны.
event_df = event_df.sort_values('id')
sessions_start_df = sessions_start_df.sort_values('id')
event_df = pd.merge_asof(event_df,sessions_start_df[['id','user_id','session_id']],on='id',by='user_id')В итоге получаем вот такой распрекрасный объединенный датафрейм, в котором в колонке ’session_id’ указан уникальный идентификатор сессии:
Дополнительные манипуляции
1 Найдем события, которые были первыми в сессиях. Это будет полезно, если мы захотим определить страницы входа.
Обнаружить эти события предельно просто: их идентификаторы будут равны идентификаторам сессии. Для этого создадим колонку ’is_first_event_in_session’, в которой сравним между собой значения колонок ’id’ и ’session_id’.
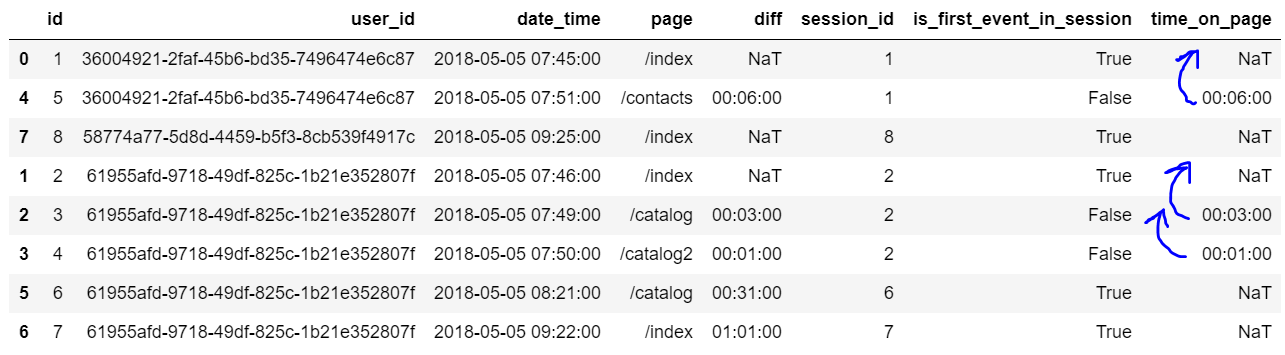
event_df['is_first_event_in_session'] = event_df['id'] == event_df['session_id']2 Вычислим время, проведенное на странице, руководствуясь временем посещения следующей страницы
Для этого сначала считаем разницу между предыдущей и следующей страницей внутри сессии. Мы уже делали такое вычисление, когда считали разницу между временем посещения страниц пользователем. Только тогда мы группировали по ’user_id’, а теперь будем по ’session_id’.
event_df['time_on_page'] = event_df.groupby(['session_id'])['date_time'].diff(1)Но diff со смещением в 1 строку считает разницу между посещением последующей страницы относительно предыдущей, поэтому время пребывания на предыдущей странице будет записано в строку следующего события:
Нам нужно сдвинуть значение столбца ’time_on_page’ на одну строку вверх внутри отдельно взятой сессии. Для этого нам пригодится функция shift.
event_df['time_on_page'] = event_df.groupby(['session_id'])['time_on_page'].shift(-1)Получили то, что нужно:
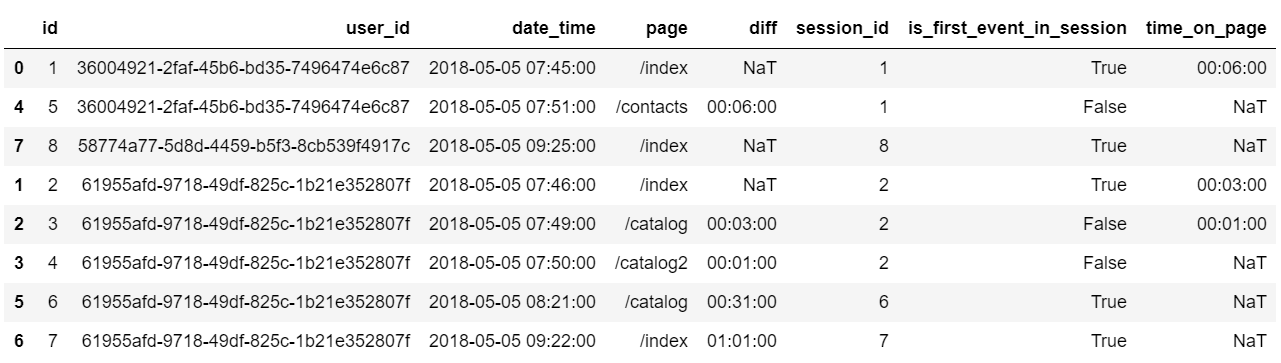
Значения в столбце ’time_on_page’ имеют специфический тип datetime64, который не всегда удобен для арифметических операций, поэтому преобразуем ’time_on_page’ в секунды.
event_df['time_on_page'] = event_df['time_on_page'] / np.timedelta64(1, 's')Вуаля:
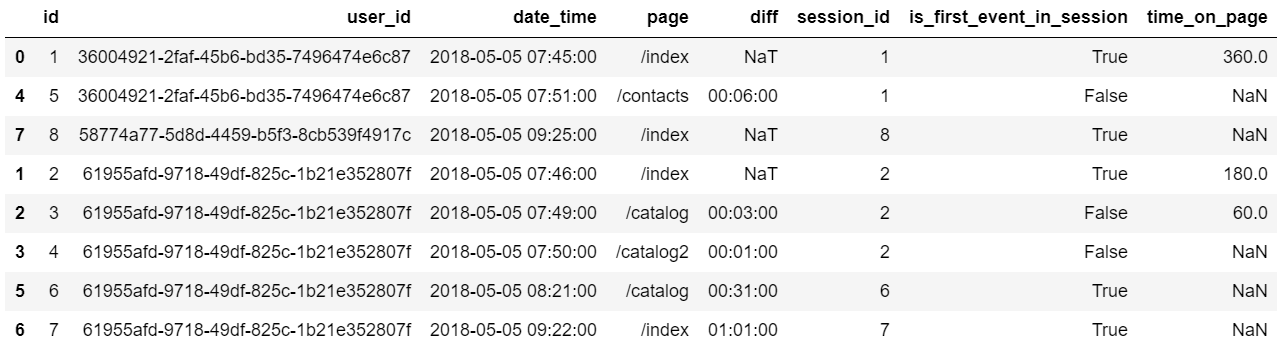
3 На основе полученных данных очень просто посчитать различные агрегаты
event_df['user_id'].nunique() # Количество пользователей
event_df['session_id'].nunique() # Количество сессий
event_df['id'].count() # Количество просмотров страниц (событий)
event_df['time_on_page'].mean() # Среднее время просмотра страниц
Заключение
Таким образом, используя несколько не самых очевидных функций в Pandas (например, merge_asof мне довелось применять впервые), можно формировать сессии на основе лога событий. Логом событий могут выступать логи сервера, какой-нибудь клик-стрим в SaaS-сервисах, сырые данные систем веб-аналитики.
Удачи и новых аналитических достижений!
Вступайте в группу на Facebook и подписывайтесь на мой канал в Telegram, там публикуются интересные статьи про анализ данных и не только.
Большое спасибо. Задача похожая на эту стоит сейчас у меня.
Успехов!