
Головоломка про рандомный сэмпл
Введение
Иногда чтение чужого кода бывает крайне интересным и увлекательным, будто читаешь отличный нон-фикшн. Чаще бывает, что читаешь и понимаешь, что автор вообще не думал о том, что кто-то будет читать его творение. Будто намеренно обфусцировал. Еще бы переменные называл a,b,c,d и тогда можно было бы даже не пробовать разбираться.
И вот читая один ноутбук, я наткнулся на конструкцию, которая по началу ввела в ступор:
df.loc[df.index.isin(df.sample(int(len(df)*0.1)).index), 'some_column'] = 1Немного подумав, я сообразил что таким образом делает автор и это решение показалось достаточно интересным, хотя и не достаточно прозрачным. Задача этой строчки кода — задать значение 1 в колонке some_column для 10% случайных строк в датафрейм.
У многих может возникнуть вопрос зачем вообще может понадобится такая операция. В изначальном ноутбуке этот кусок кода использовался, чтобы создать тестовый набор данных, обладающий заданными характеристиками: 10% должны были быть единицами, еще 20% двойками и т. д.
В этой статье мы детально разберем как работает эта отдельно взятая строчка кода (да, целая статья ради строчки кода, так она меня вдохновила). На самом деле, в этой строчке заложен целый алгоритм. Мы поэтапно рассмотрим каждый этап работы этого алгоритма. Это может быть полезно для начинающих изучать Pandas (и Python в целом) в качестве примера того, что даже странные вещи при декомпозиции кажутся простыми и понятными.
Создание тестового датафрейма
Первое, что мы сделаем — это создадим тестовый датафрейм.
Сначала создаем массив numpy (numpy.array) с помощью функции np.random.randint. Эта функция позволяет создать массив numpy заданной размерности (size) и заполнить его случайными целыми числами из определенного диапазона. Нижняя граница диапазона задается в параметре low, а верхняя — в high. Создадим двумерный массив размерностью 100 на 5 (или 100 массивов по 5 элементов в каждом) со случайными числами от 0 до 9 включительно и запишем его в переменную random_array:
import numpy as np
import pandas as pd
random_array = np.random.randint(low=0,high=10,size=(100,5))
display(random_array)Out:

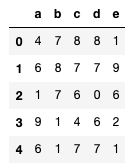
Из получившегося numpy-массива random_array сделаем датафрейм df:
df = pd.DataFrame(random_array,columns=['a','b','c','d','e'])
display(df.head())Out:
Декомпозируй это
А теперь приступим по кусочкам разбирать исходную строку кода. Немного изменим её и вместо имени колонки some_column зададим имя колонки, которая уже присутствует в нашем датафрейме df, например, колонку e:
df.loc[df.index.isin(df.sample(int(len(df)*0.1)).index), 'e'] = 1Мы будем записывать каждый этап алгоритма в отдельную переменную, чтобы повысить читабельность кода.
1. Определение длины датафрейма
Начнем с конструкции len(df):
Тут всё просто — стандартная питоновская функция len при передаче в неё датафрейма возвращает его длину. Запишем результат в переменную count_of_rows. Ожидаемо, count_of_rows у нас будет равняться 100:
count_of_rows = len(df)
print(count_of_rows)Out:
2. Определение размера случайной выборки
Посмотрим что происходит на следующем этапе:
Тут полученное количество строк умножается на 0.1 и затем приводится к целому числу. То есть мы получаем 1/10 от длины датафрейма df. Запишем результат в переменную sample_size. В нашем случае это будет число 10:
sample_size = int(count_of_rows*0.1)
print (sample_size)Out:
3. Формирование случайной выборки
Дальше нас встречает функция sample:
Эта функция нужна для получения случайной выборки из датафрейма. Мы передаем в функцию sample значение sample_size, тем самым указывая, что нам нужна выборка заданного размера (10 строк) и записываем выборку в переменную sample_from_df:
sample_from_df = df.sample(sample_size)
display(sample_from_df)Out:
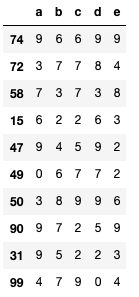
Обратите внимание, что датафрейм с выборкой, которую мы получили имеет индексы исходного датафрейма df. Если вам не понятно что такое индексы, то всё должно стать понятнее если назвать их номерами строк. Таким образом, мы легко понимаем какие именно случайные строки были выбраны для случайной выборки.
4. Получение индекса из случайной выборки
Следующий шаг — получение индекса строк из образовавшейся выборки:
Полученные индексы запишем в переменную index_of_sample_from_df:
index_of_sample_from_df = sample_from_df.index
display(index_of_sample_from_df)Out:
5. Создание маски для выборки
Дальше нас встречает конструкция с оператором //isin:
На самом деле, isin тут лишний, но как оптимизировать этот код, убрав из него эту конструкцию, я расскажу в конце статьи.
Итак, что же делает функция isin? Когда она применяется к индексу, то она возвращает массив булевых (True/False) значений, где True будет соответствовать тем строкам датафрейма df, индексы которых находятся в массиве index_of_sample_from_df, а False — всем остальным строкам. Запишем такой массив в переменную binary_mask:
binary_mask = df.index.isin(index_of_sample_from_df)
display(binary_mask)Out:

6. Присвоение значения в соответствии с маской
И последний этап нашего алгоритма — присвоить значение 1 в колонке e строкам датафрейма df, которые попали в случайную 10ти-процентную выборку:
Такие строки как раз можно выделить из датафрейма df, передав битовую маску binary_mask в функцию loc.
Таким образом, функция loc позволяет нам выбрать строки в соответствии с порядковыми номерами элементов массива binary_mask, которые равняются True, а также задать колонку e, значение которой надо изменить. На словах это звучит сложно, но всё станет ясно, когда мы применим функцию и посмотрим на результат:
df.loc[binary_mask, 'e'] = 1
display(df.loc[binary_mask])Out:
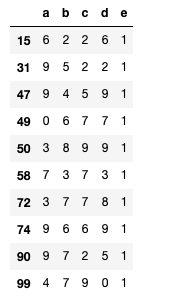
Обратите внимание на индекс этой выборки. Он совпадает с индексом случайной выборки index_of_sample_from_df. Так и задумывалось! :)
df.loc[binary_mask].index == sorted(sample_from_df.index)Out:
Заключение
Таким образом, рассмотрев одну строчку кода мы рассмотрели небольшой алгоритм преобразования данных и углубились внутрь работы множества функций Pandas: sample, index, isin, loc.
Можно ли было проще?
В завершение рассмотрим как можно было бы сделать этот код чуть более легким. На самом деле, нет нужды в использовании конструкции df.index.isin. Хотя в некоторых случаях, от этой функции есть польза, например, при работе с мультииндексами, но об этом как-нибудь в другой раз.
Переменная index_of_sample_from_df уже содержит индексы строк, передав которые в loc вместо binary_mask мы получим выборку строк в соответствии с индексами:
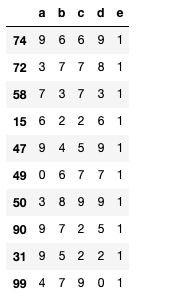
df.loc[index_of_sample_from_df, 'e'] = 1
display(df.loc[index_of_sample_from_df])Out:
Учитывая это, наш код можно было бы сократить:
df.loc[df.sample(int(len(df)*0.1)).index, 'e'] = 1Или в более читабельном, но более длинном, виде:
count_of_rows = len(df)
sample_size = int(count_of_rows*0.1)
sample_from_df = df.sample(sample_size)
index_of_sample_from_df = sample_from_df.index
df.loc[index_of_sample_from_df, 'e'] = 1Я уверен, что у этой задачи есть и другие решения. Если вам придёт в голову своё решение — не стесняйтесь писать в комментариях.
На этом всё. Спасибо, что читаете!
Успехов!
Добрый день!
У функции sample есть аргумент frac. Мне кажется df.sample(int(len(df)*0.1)).index можно было бы записать как df.sample(frac=0.1).index.
Женя
Да, действительно, frac тут помог бы! Спасибо!