
Как использовать Google BigQuery с помощью Python
Что такое Google BigQuery

Google BigQuery — это безсерверное масштабируемое хранилище данных. Использование безсерверного (облачного) решения — хорошая идея, если у вас нет серьезного бэкграунда в администрировании баз данных. Такой подход позволяет сосредоточиться только на анализе данных, и не думать об инфраструктуре хранения данных (шардировании, индексации, компрессии). BigQuery поддерживает стандартный диалект SQL, так что любой, кто когда-либо пользовался SQLными СУБД, с легкостью может начать им пользоваться.
Начало работы с Google BigQuery и создание ключа для сервисного аккаунта
Я не буду подробно объяснять о том как начать работу с Google Cloud Platform и завести первый проект, об этом хорошо написано в статье Алексея Селезнева в блоге Netpeak. Когда у нас уже есть проект в Cloud Platform с подключенным API BigQuery, следующим шагом нужно добавить учетные данные.
- Переходим в раздел «API и сервисы > Учетные данные»:
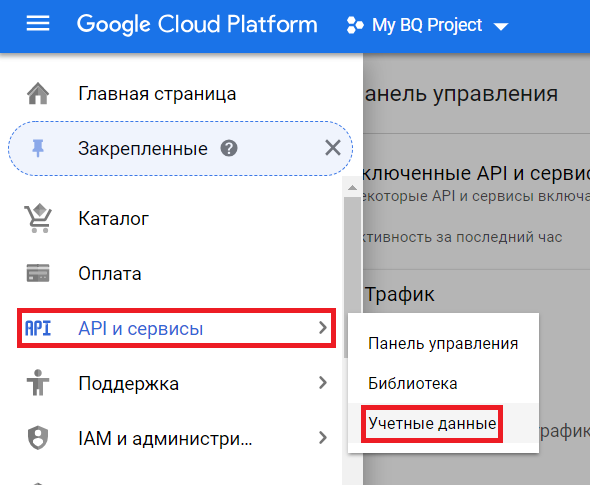
- Нажимаем «Создать учетные данные > Ключ сервисного аккаунта»
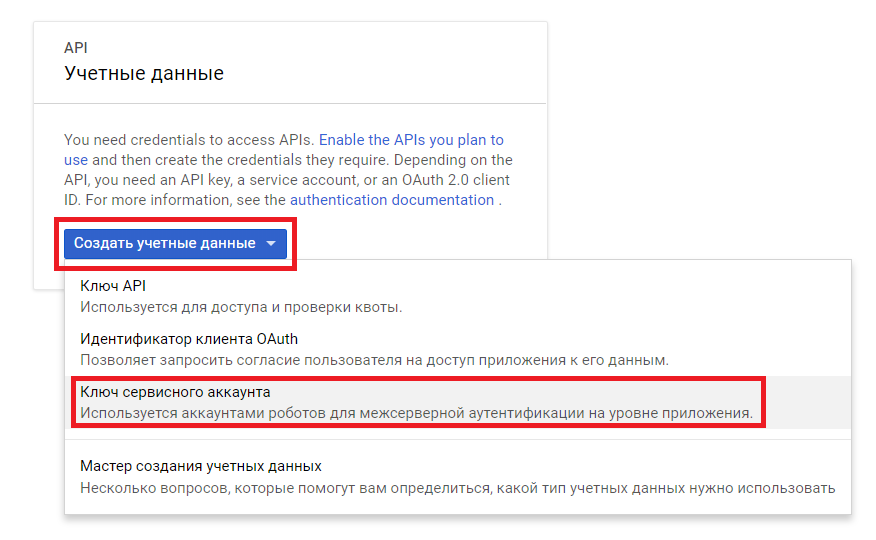
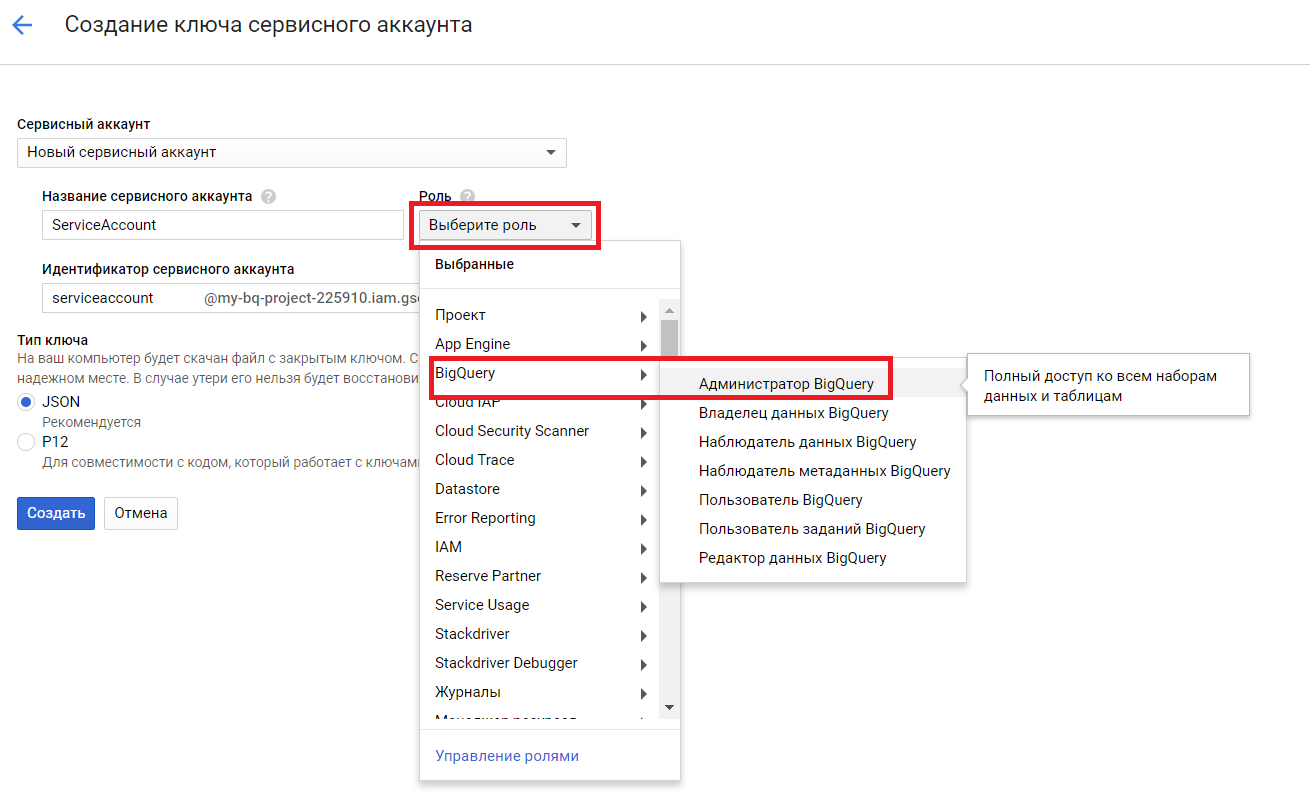
- Заполняем параметры: пишем название сервисного аккаунта; выбираем роль (как показано на скриншоте ниже, но роль может зависеть от уровня доступов, которые вы хотите предоставить сервисному аккаунту); выбираем тип ключа JSON; нажимаем «Создать»
- Переходим в раздел «IAM и администрирование > Сервисные аккаунты»
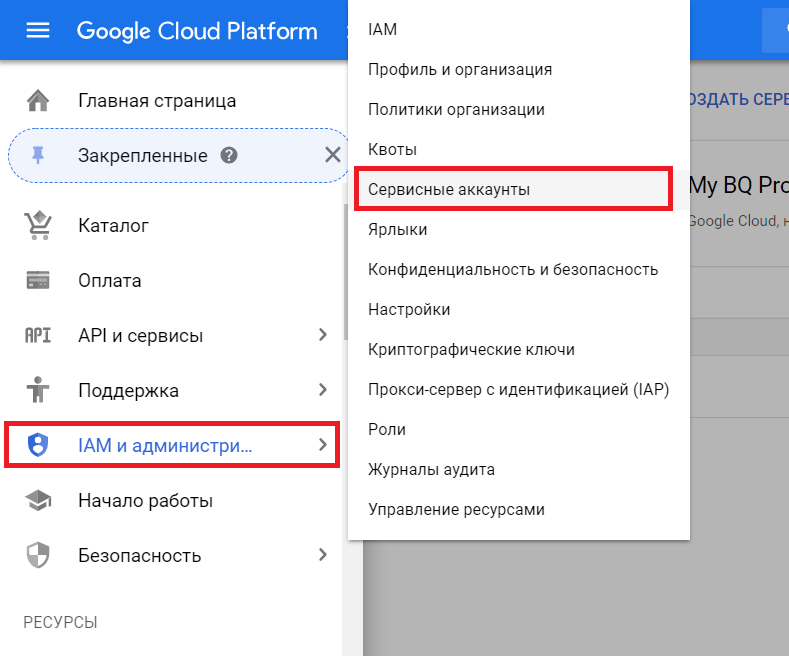
- В колонке «Действия» для созданного нами сервисного аккаунта выбираем «Создать ключ»
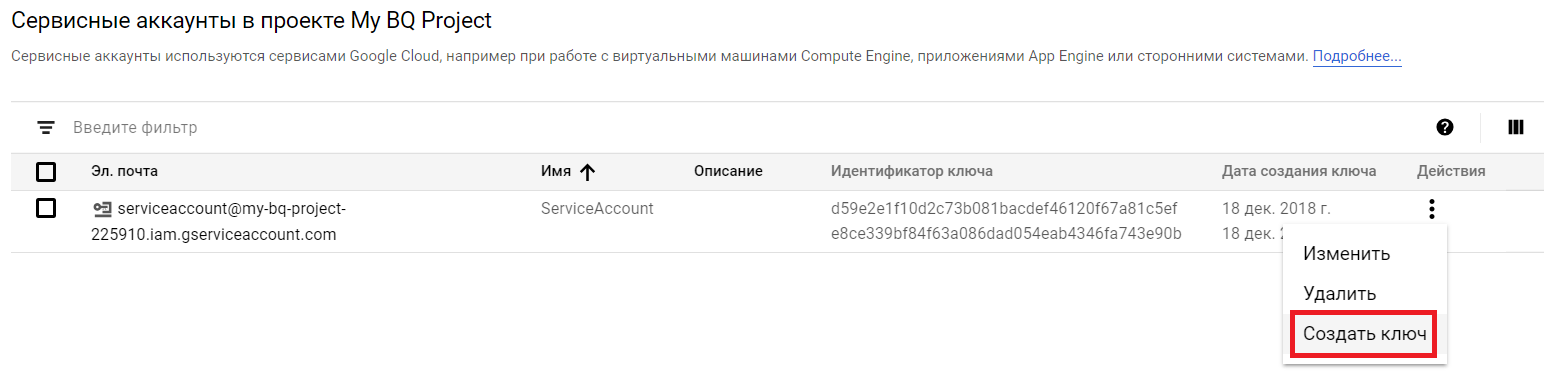
- Выбираем формат ключа «JSON» и нажимаем создать, после чего будет скачан JSON-файл, содержащий авторизационные данные для аккаунта
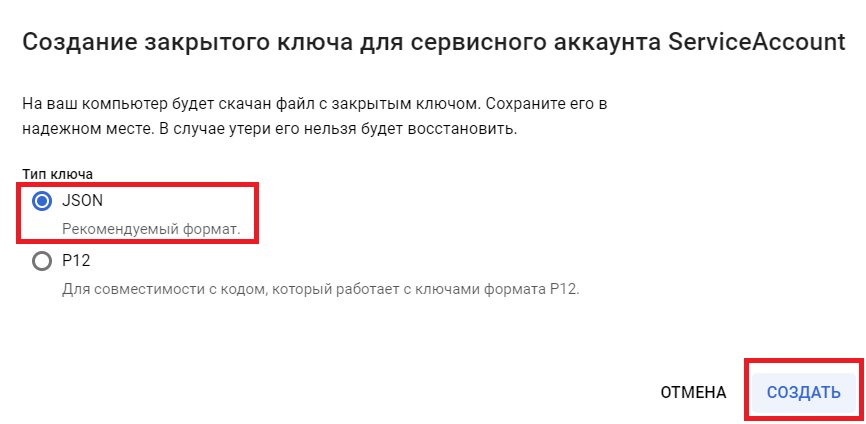
Полученный JSON с ключом нам понадобится в дальнейшем. Так что не теряем.
Использование pandas-gbq для импорта данных из Google BiqQuery
Первый способ, с помощью которого можно загружать данные из BigQuery в Pandas-датафрейм — библиотека pandas-gbq. Эта библиотека представляет собой обертку над API Google BigQuery, упрощающая работу с данными BigQuery через датафреймы.
Сначала нужно поставить библиотку pandas-gbq. Это можно сделать через pip или conda:
pip install pandas-gbq
conda install pandas-gbq -c conda-forgeЯ решил рассмотреть основы работы с Google BigQuery с помощью Python на примере публичных датасетов. В качестве интересного примера возьмем датасет с данными о вопросах на сервисе Stackoverflow.
import pandas as pd
from google.oauth2 import service_account
# Прописываем адрес к файлу с данными по сервисному аккаунту и получаем credentials для доступа к данным
credentials = service_account.Credentials.from_service_account_file(
'my-bq-project-225910-6e534ba48078.json')
# Формируем запрос и получаем количество вопросов с тегом "pandas", сгруппированные по дате создания
query = '''
SELECT DATE(creation_date) as date, COUNT(id) as questions
FROM
[bigquery-public-data:stackoverflow.posts_questions]
WHERE tags LIKE '%pandas%'
GROUP BY
date
'''
# Указываем идентификатор проекта
project_id = 'my-bq-project-225910'
# Выполняем запрос с помощью функции ((https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_gbq.html read_gbq)) в pandas, записывая результат в dataframe
df = pd.read_gbq(query, project_id=project_id, credentials=credentials)
display(df.head(5))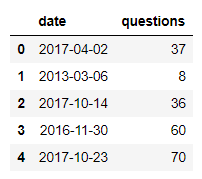
Важное примечание: По умолчанию функция read_gbq в pandas использует диалект legacy SQL. Для того, чтобы задать диалект standart SQL нужно воспользоваться параметром dialect:
df = pd.read_gbq(query, project_id=project_id, credentials=credentials, dialect='standard')Дальше немного поиграем с обработкой данных. Выделим из даты месяц и год.
df['month'] = df['date'].values.astype('datetime64[M]') # Создаем новый столбец с месяцем
df['year'] = df['date'].values.astype('datetime64[Y]') # Создаем новый столбец с годом
# Отображаем один день с максимальным количеством вопросов
display(df.sort_values('questions',ascending=False).head(1))
Cгруппируем данные по годам и месяцам и запишем полученные данные в датафрейм stats
stats = df.groupby(['year','month'],as_index=False).agg({'questions':'sum'}) # Группируем данные по году и месяцу, используя в качестве агрегирующей функции сумму количества вопросов
display(stats.sort_values('questions',ascending=False).head(5))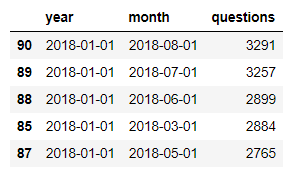
Посчитаем суммарное количество вопросов в год, а также среднее количество запросов в месяц для каждого года, начиная с января 2013 и по август 2018 (последний полный месяц, который был в датасете на момент написания статьи). Запишем полученные данные в новый датафрейм year_stats
year_stats = stats[(stats.month >= '2013-01-01') & (stats.month < '2018-09-01')].groupby(['year'],as_index=False).agg({'questions':['mean','sum']})
display(year_stats)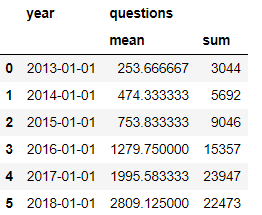
Так как 2018 год в наших данных неполный, то мы можем посчитать оценочное количество вопросов, которое ожидается в 2018 году.
year_stats['estimate'] = year_stats[('questions','mean')]*12
display(year_stats)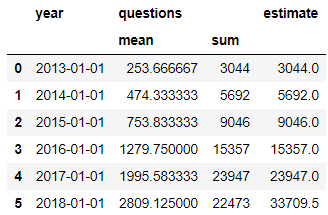
На основе данных от StackOverflow, можно сказать, что популярность pandas из года в год растёт хорошими темпами :)
Запись данных из dataframe в Google BigQuery
Следующим шагом, я хотел бы показать как записывать свои данные в BigQuery из датафрейма с помощью pandas_gbq.
В датафрейме year_stats получился multiindex из-за того, что мы применили две агрегирующие функции (mean и sum). Чтобы нормально записать такой датафрейм в BQ надо убрать multiindex. Для этого просто присвоим dataframe новые колонки.
year_stats.columns = ['year','mean_questions','sum_questions','estimate']После этого применим к датафрейму year_stats функцию to_gbq. Параметр if_exists = ’fail’ означает, что при существовании таблицы с таким именем передача не выполнится. Также в значении этого параметра можно указать append и тогда к существующим данным в таблице будут добавлены новые. В параметре private_key указываем путь к ключу сервисного аккаунта.
year_stats.to_gbq('my_dataset.my_table', project_id=project_id, if_exists='fail', private_key='my-bq-project-225910-6e534ba48078.json')После выполнения функции в BigQuery появятся наши данные:
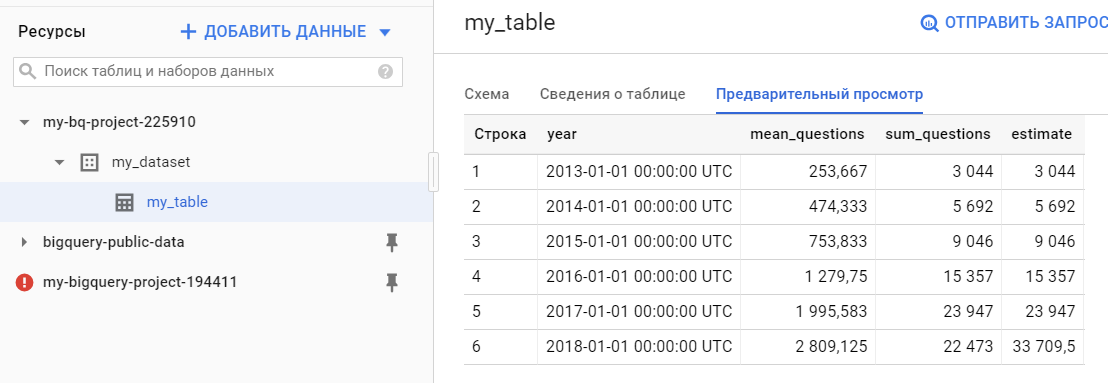
Итак, мы рассмотрели импорт и экспорт данных в BiqQuery из Pandas’овского датафрейма с помощью pandas-gbq. Но pandas-gbq разрабатывается сообществом энтузиастов, в то время как существует официальная библиотека для работы с Google BigQuery с помощью Python. Основные сравнения pandas-gbq и официальной библиотеки можно посмотреть тут.
Использование официальной библиотеки для импорта данных из Google BiqQuery
Прежде всего, стоит поблагодарить Google за то, что их документация содержит множество понятных примеров, в том числе на языке Python. Поэтому я бы рекомендовал ознакомиться с документацией в первую очередь.
Ниже рассмотрим как получить данные с помощью официальной библиотеки и передать их в dataframe.
from google.cloud import bigquery
client = bigquery.Client.from_service_account_json(
'/home/makarov/notebooks/my-bq-project-225910-6e534ba48078.json')
sql = '''
SELECT DATE(creation_date) as date, DATE_TRUNC(DATE(creation_date), MONTH) as month, DATE_TRUNC(DATE(creation_date), YEAR) as year, COUNT(id) as questions
FROM
`bigquery-public-data.stackoverflow.posts_questions`
WHERE tags LIKE '%pandas%'
GROUP BY
date, month, year
'''
project_id = 'my-bq-project-225910'
df2 = client.query(sql, project=project_id).to_dataframe()
display(df2.head(5))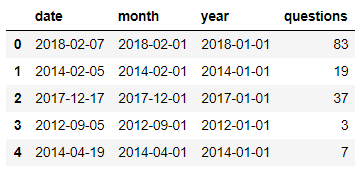
Как видно, по простоте синтаксиса, официальная библиотека мало чем отличается от использования pandas-gbq. При этом я заметил, что некоторые функции, (например, date_trunc), не работают через pandas-gbq. Так что я предпочитаю использовать официальное Python SDK для Google BigQuery.
По умолчанию в официальном SDK используется диалект Standard SQL, но можно использовать Legacy SQL. С примером использования Legacy SQL можно ознакомиться по ссылке.
Чтобы импортировать данные из датафрейма в BigQuery нужно установить pyarrow. Эта библиотека обеспечит унификацию данных в памяти, чтобы dataframe соответствовал структуре данных, нужных для загрузки в BigQuery.
# Создаем тестовый dataframe
df = pd.DataFrame(
{
'my_string': ['a', 'b', 'c'],
'my_int64': [1, 2, 3],
'my_float64': [4.0, 5.0, 6.0],
}
)
dataset_ref = client.dataset('my_dataset_2') # Определяем датасет
dataset = bigquery.Dataset(dataset_ref)
dataset = client.create_dataset(dataset) # Создаем датасет
table_ref = dataset_ref.table('new_table') # Определяем таблицу (при этом не создавая её)
result = client.load_table_from_dataframe(df, table_ref).result() # Тут данные из датафрейма передаются в таблицу BQ, при этом таблица создается автоматически из определенной в предыдущей строкеПроверим, что наш датафрейм загрузился в BigQuery:
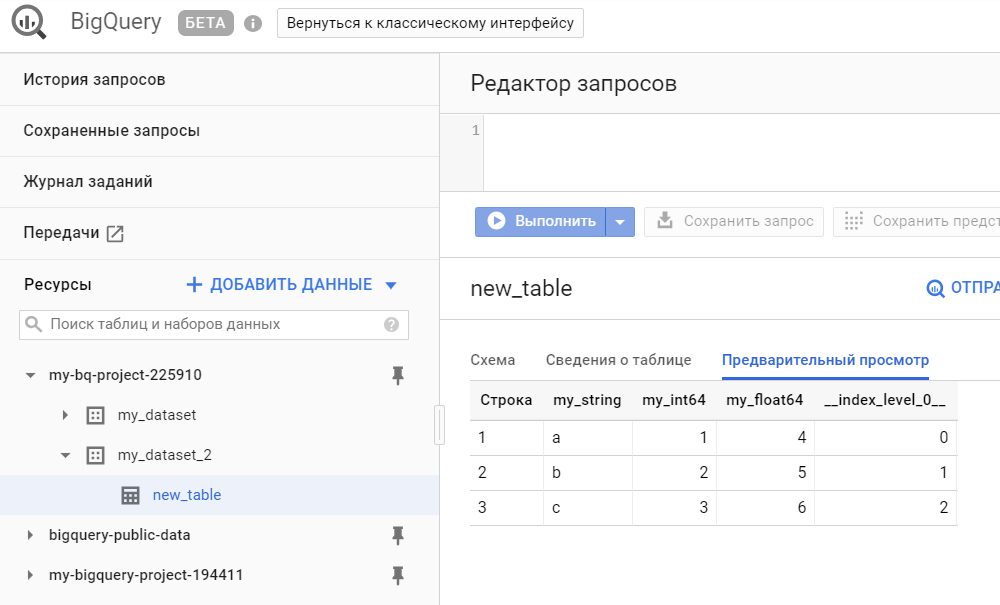
Прелесть использования нативного SDK вместо pandas_gbq в том, что можно управлять сущностями в BigQuery, например, создавать датасеты, редактировать таблицы (схемы, описания), создавать новые view и т. д. В общем, если pandas_gbq — это скорее про чтение и запись dataframe, то нативное SDK позволяет управлять всей внутренней кухней
Ниже привожу простой пример как можно изменить описание таблицы
table = client.get_table(table_ref) # Получаем данные о таблице
table.description = 'Моя таблица' # Задаем новый дескрипшн для таблицы
table = client.update_table(table, ['description']) # Обновляем таблицу, передав новый дескрипшн через API
print(table.description)Также с помощью нативного Python-SDK можно вывести все поля из схеме таблицы, отобразить количество строк в таблице
for schema_field in table.schema: # Для каждого поля в схеме
print (schema_field) # Печатаем поле схемы
print(table.num_rows) # Отображаем количество строк в таблице
Если таблица уже создана, то в результате новой передачи датафрейма в существующую таблицу будут добавлены строки
result = client.load_table_from_dataframe(df, table_ref).result() # Передаем данные из dataframe в BQ-table
table = client.get_table(table_ref) # Заново получаем данные о таблице
print(table.num_rows) # Отображаем новое количество строкЗаключение
Вот так, с помощью несложных скриптов, можно передавать и получать данные из Google BigQuery, а также управлять различными сущностями (датасетами, таблицами) внутри BigQuery.
Успехов!
Вступайте в группу на Facebook и подписывайтесь на мой канал в Telegram, там публикуются интересные статьи про анализ данных и не только.
Не получается установить pyarrow для записи данных в из датафрэйма в bq (выдает ошибку), есть какая-то альтернатива pyarrow?
Скажите, сейчас этот способ работает?
Нужны ли еще какие-то дополнительные скрипты?
Спасибо!!!