
Как в Pandas разбить одну колонку на несколько
Введение в задачу
Решил начать рассматривать нетривиальные кейсы в Pandas, с которыми иногда сталкиваюсь при работе с данными. Опять же, нетривиальные они только на мой взгляд, потому что какие-то вещи я решаю впервые и они заставляют немного подумать :) Возможно, такие небольшие кейсы помогут аналитикам, если они увидят в своих «затыках» что-то похожее. Также, я не претендую на абсолютную правильность или универсальность решения. Таким образом, у подобной задачи может быть несколько правильных решений. Я буду рад, если в комментариях вы будете предлагать свои решения. Касательно универсальности решения, тут я имею в виду, что решение может быть применимо к конкретному датасету, но при этом может не работать, если датасет будет иметь какие-то существенные видоизменения.
Первой из задач, которой я бы хотел поделиться, будет разбивка колонки датафрейма на несколько отдельных колонок с добавление к существующему датафрейму. Казалось бы просто. Давайте посмотрим решение.
Итак, у меня есть вот такой dataframe:

Выведем первое значение из колонки new_values, чтобы лучше понять что же нам надо сделать:

Как видно, значения разделены знаком переноса строки (\n), а также каждое значение представлено в виде ключ=значение (например, ключом выступает date_start, а значением 2018-12-04).
Задача состоит в том, чтобы привести датафрейм к вот такому виду:

Решение №1
Итак, первое решение будет простым и достаточно коротким.
Сначала, нам понадобится пандосовская функция str.split (https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.str.split.html). Она просто разбивает столбец на список на основании разделителя
df['new_values'].str.split('\n')
Вот как выглядит отдельное значение:
df['new_values'].str.split('\n')[0]Но у функции str.split есть замечательный параметр expand=True, позволяющий сразу сделать разбиение на колонки и получить датафрейм
new_df = df['new_values'].str.split('\n',expand=True)
new_df
Таким образом, мы получили дополнительный датафрейм new_df, который содержит результат разбиения. Дальше переименуем колонки датафрейма, чтобы каждая из них содержала название соответствующего ключа:
new_df.columns=['date_start','component','customer']
new_df
Затем нам нужно избавиться в колонках от названия ключа и знака «равно». Сделаем это простым циклом с функцией str.replace (https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.str.replace.html):
for column in new_df.columns:
new_df[column] = new_df[column].str.replace(column+'=','')
new_df
Осталось только соединить два датафрейма (исходный df и new_df) с помощью функции pd.concat (https://pandas.pydata.org/pandas-docs/version/0.23.4/generated/pandas.concat.html). Обратите внимание на параметр axis=1, который позволяет соединить датафреймы по столбцам, а не по строкам
final_df = pd.concat([df,new_df],axis=1)
final_df
Ну и выкинем из получившегося датафрейма ненужный нам теперь столбец new_values с помощью drop (https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.drop.html):
final_df = final_df.drop('new_values',axis=1)
final_df
Итоговый код для решения задачи выглядит так:
df = pd.read_csv('sample_data_1.csv')
new_df = df['new_values'].str.split('\n',expand=True)
new_df.columns=['date_start','component','customer']
for column in new_df.columns:
new_df[column] = new_df[column].str.replace(column+'=','')
final_df = pd.concat([df,new_df],axis=1).drop('new_values',axis=1)Решение №2
Другой способ, который я покажу, является более универсальным.
Представим, что исходный датафрейм отличается от того, что я показывал выше.

Этот датафрейм отличается тем, что в некоторых строках колонки new_values отсутствует параметр date_start. Из-за этого при попытке сделать str.split с параметром expand=True мы получим вот такой датафрейм:
df['new_values'].str.split('\n',expand=True)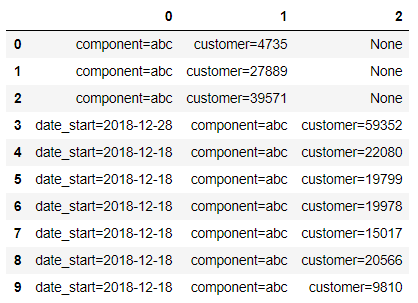
В этом случае, мы не сможем просто пройтись циклом по колонкам и получить нужные значения, так как значения по ключу не всегда однозначно находятся в одной колонке, а могут быть разбросаны по нескольким. Такая же ситуация могла бы быть, если бы перечисление значений шло не в одном порядке, а по-разному. Например в одной строке date_start=2018-12-28\ncomponent=abc\ncustomer=59352, а в другой component=abc\ncustomer=22080\ndate_start=2018-12-18
Чтобы обойти эту проблему нам нужно преобразовать эти данные в такую структуру, которую было бы удобно запихнуть в датафрейм и pandas сам бы смог разделить данные по нужным колонкам, опираясь на структуру данных. Одной из таких структур может быть список словарей (list of dicts). В виде списка словарей данные должны выглядеть вот так:

Когда мы получим такую структуру, то потом сможем преобразовать её в датафрейм, а полученный датафрейм соединить с исходным (как мы уже это делали выше с помощью функции pd.concat).
Итак, первое что мы сделаем, это разобъем колонку с помощью уже знакомой функции str.split, но без параметра expand=True. Это позволит нам сделать отдельный series, содержащий списки:
s = df['new_values'].str.split('\n')
s
Затем каждый из списков нам нужно преобразовать к словарю. То есть совершить вот такое преобразование:
Чтобы лучше понять суть преобразования покажу на примере одного списка s[0], а затем сделаем функцию, которую применим к каждому элементу в series.
Сначала сделаем внутри списка s[0] вложенные списки, сделав split каждого из элемента списка по знаку «равно» через list comprehension (подробнее про list comprehension можно прочитать в статье, скажу только, что это очень удобно):
splited_items = [a.split('=') for a in s[0]]
splited_itemsЗатем полученный список splited_items надо переделать в словарь. Для этого сделаем несложное преобразование — создадим словарь, после чего пройдемся циклом по каждому вложенному списку и назначим нулевой элемент вложенного списка ключом словаря, а первый элемент — значением по ключу:
dictionary = {}
for item in splited_items:
key = item[0]
value = item[1]
dictionary[key] = value
dictionaryСделаем функцию, которая делает вышеописанное преобразование:
def convertToDict(x):
splited_items = [a.split('=') for a in x]
dictionary = {}
for item in splited_items:
key = item[0]
value = item[1]
dictionary[key] = value
return dictionaryПосле этого можно применить функцию к серии s с помощью apply (https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.apply.html):
s = s.apply(lambda x: convertToDict(x))
s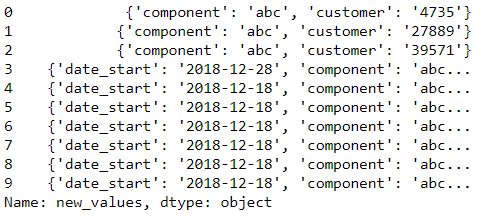
Затем применим функцию pd.Series к каждому из словарей, таким образом преобразовав каждый словарь в series, а вместе последовательность series образует датафрейм:
new_df = s.apply(pd.Series)
new_df
Следующим шагом соединим датафрейм new_df с исходным df и уберем столбец с помощью функции drop:
final_df = pd.concat([df,new_df],axis=1).drop('new_values',axis=1)
final_df
Итоговый код для обработки данных выглядит вот так:
def convertToDict(x):
splited_items = [a.split('=') for a in x]
dictionary = {}
for item in splited_items:
key = item[0]
value = item[1]
dictionary[key] = value
return dictionary
df = pd.read_csv('sample_data_2.csv')
s = df['new_values'].str.split('\n')
s = s.apply(lambda x: convertToDict(x))
new_df = s.apply(pd.Series)
final_df = pd.concat([df,new_df],axis=1).drop('new_values',axis=1)И в качестве бонуса, можно сделать код более удобочитаемым с помощью method chaining:
df = pd.read_csv('sample_data_2.csv')
new_df = df['new_values'].str.split('\n').\
apply(lambda x: convertToDict(x)).\
apply(pd.Series)
final_df = pd.concat([df,new_df],axis=1).drop('new_values',axis=1)Решение Романа Шапкова
UPD от 30.01.2019:
Читатель Роман решил эту задачу с помощью регулярных выражений
import pandas as pd
import re
df = pd.read_csv('sample_data_2.csv')
pattern_date = '(\d{4}-\d{2}-\d{2})'
pattern_ncomp = 'component=(\w*)'
pattern_ncust = 'customer=(\d*)'
def find_pattern(string, pattern):
"""
аргументы: string - текстовая строка для поиска
pattern - шаблон регулярного выражения
функция осуществляет поиск шаблона "pattern" в строке "string" используя правила регулярных выражений(RegExp).
Если шаблон найден - возвращает значение, иначе - возвращает None
"""
if re.search(pattern, string):
return re.search(pattern, string).group(1)
df['start_date'] = df['new_values'].apply(lambda x: find_pattern(x,pattern_date))
df['component'] = df['new_values'].apply(lambda x: find_pattern(x,pattern_ncomp))
df['customer'] = df['new_values'].apply(lambda x: find_pattern(x,pattern_ncust))
dfЗаключение
На этом всё. Надеюсь, этот пример решения задачи кто-то найдет интересным и научится из него каким-то новым приёмам в своей работе. Это причина, по который я решил выкладывать такие примеры — не просто рассказывать про то, как работают функции в pandas или предлагать готовые решения, а показать последовательность действий и методологию решения задачи, чтобы читатели могли перенести части этого решения в свои проекты.
Если пост оказался полезным, то буду рад отзывам в комментариях, это будет для меня сигналом, что подобные вещи надо продолжать делать. А ещё лучше пишите как бы вы решили такую задачу, скидывайте примеры решений.
Вступайте в группу на Facebook и подписывайтесь на мой канал в Telegram, там публикуются интересные статьи про анализ данных и не только.
я бы сделал использую RegExp(регулярные выражения).
Как по мне это гораздо проще и куда более гибче!
Пример кода ниже...
_________________________________________
import pandas as pd
import re
df = pd.read_csv(’sample_data_2.csv’)
pattern_date = ’(\d{4}-\d{2}-\d{2})’
pattern_ncomp = ’component=(\w*)’
pattern_ncust = ’customer=(\d*)’
def find_pattern(string, pattern):
«„“
аргументы: string — текстовая строка для поиска
pattern — шаблон регулярного выражения
функция осуществляет поиск шаблона „pattern“ в строке „string“ используя правила регулярных выражений(RegExp).
Если шаблон найден — возвращает значение, иначе — возвращает None
„„“
if re.search(pattern, string):
return re.search(pattern, string).group(1)
df[’start_date’] = df[’new_values’].apply(lambda x: find_pattern(x,pattern_date))
df[’component’] = df[’new_values’].apply(lambda x: find_pattern(x,pattern_ncomp))
df[’customer’] = df[’new_values’].apply(lambda x: find_pattern(x,pattern_ncust))
df
Я наверное чутка туповат и не понимаю следующий момент: мы читаем файл и делим колонки, но как сохранить все это в файл, чтобы после всех манипуляций сохранить в файл.
и правда тупой, RTFM https://riptutorial.com/ru/pandas/example/7948/%D1%81%D0%BE%D1%85%D1%80%D0%B0%D0%BD%D0%B8%D1%82%D1%8C-%D0%B2-csv-%D1%84%D0%B0%D0%B9%D0%BB%D0%B5
Решение задачи через apply будет более долгим по времени?
Функцию convertToDict можно убрать, используя list comprehensions, в одну строку:
new_df = df[’new_values’].str.split(’\n’).\
apply(lambda x: {item[0]: item[1] for item in [a.split(’=’) for a in x]}).\
apply(pd.Series)
Хотя, решение с регулярками от Романа тоже интересное.
очень круто!!! спасибо искал как все сделать в np но не нашел, а тут все элементарно!!
Алексей, а Вы не знаете можно ли как-нибудь отфильтровать массив данных, который отдает Logs API метрики? Например ym:s:goalsID отдает в формате [26783777,282511884].
Есть ли какой-нибудь хороший способ, или всё придется все рано выносить в отдельные столбцы?
я использовал (для своих целей ) df2 = df1[’ЗРА’].str.extract(r’(?P<Вид_ЗРА>[ВСДОКCOKB]{1,2})(?P<Номер>\d{3,4})’). с именованными группами — имена групп становятся названиями столбцов. Случайно нашел этот метод в документации пандас, так в русскоязычном интернете ни слова. Ну а вообще есть шутка: если у вас есть проблема и вы решили воспользоваться Регулярками — то теперь у вас две проблемы. Ну у меня получилось и я был в восторге от метода.