
Список стоп-слов Яндекс.Директа
Стоп-слова в Яндекс.Директе — это служебные части речи и местоимения, а также любые слова, не несущие дополнительного смысла, которые автоматически исключаются из запроса пользователя при отборе объявлений для показа. Например, при запросе пользователя “Как и когда купить слона” для показа будут отобраны объявления, у которых в ключевых словах присутствует фраза “Купить слона”. “Как”, “и”, “когда” будут в этом случае являться стоп-словами. Для их принудительного включения во фразу перед ними нужно поставить знак плюс, например «+как +и +когда купить слона».
Не путайте стоп-слова и минус-слова. Минус-слова — это слова, по запросам с которыми рекламное объявление показываться не будет. Минус-слова можно указать на уровне кампании, группы объявлений или ключевой фразы. Например, если мы укажем минус-слово «скачать» на уровне кампании, то ни одно из объявлений кампании не будет показываться по любым поисковым запросам пользователя, содержащим «скачать».
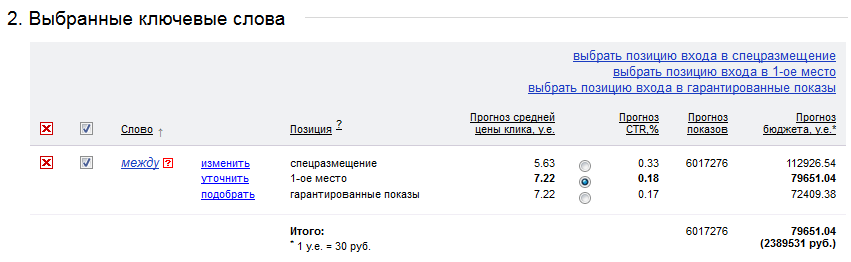
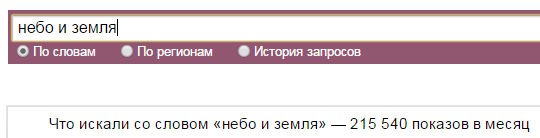
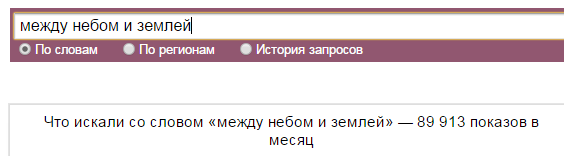
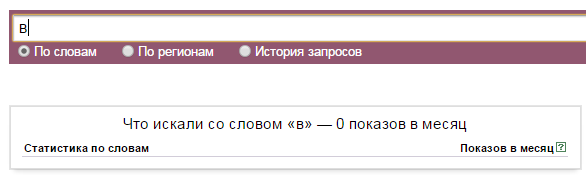
Мне понадобилось определить какие слова Яндекс.Директ считает стоп-словами. Сначала я задумал использовать для этой задачи список всех предлогов, союзов, междометий и местоимений. Но оказалось, что не все слова этих частей речи используются Директом в качестве стоп-слов. Например, союз «со» и предлог «между» к стоп-словам не относятся. Проверить это просто: если в сервис прогноза бюджета добавить предлог «в» и нажать «Посчитать», то сервис сообщит об ошибке:


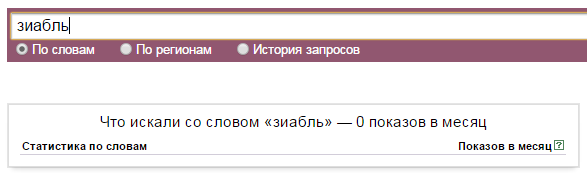
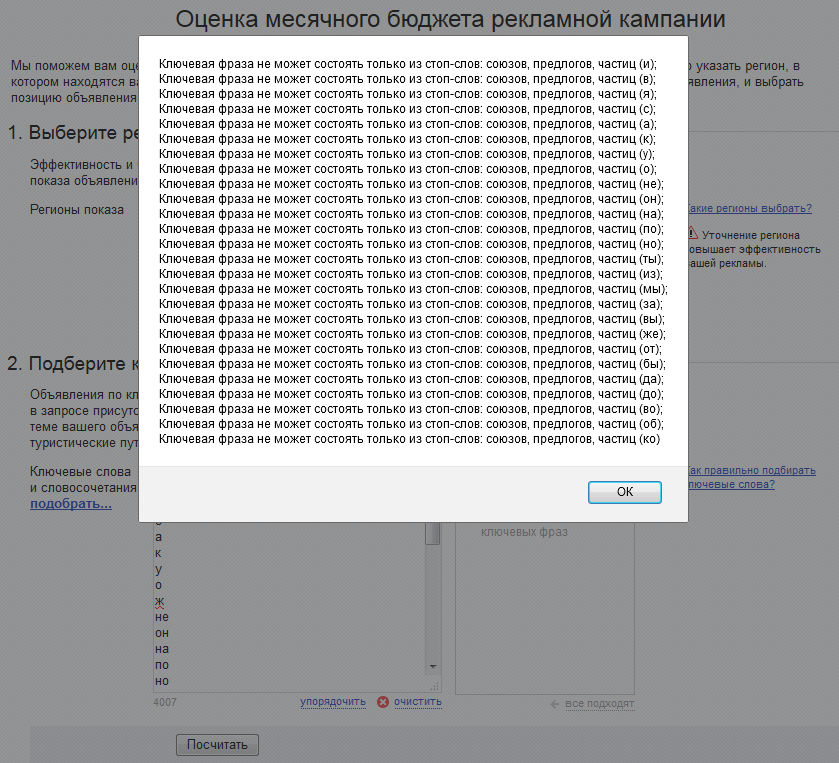

Следующим открытием было то, что ограничиваться одними лишь кириллическими словами было ошибкой:
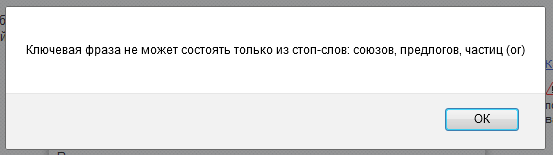
Итоговый список получился таким:
| a |
| about |
| all |
| am |
| an |
| and |
| any |
| are |
| as |
| at |
| be |
| been |
| but |
| by |
| can |
| could |
| do |
| for |
| from |
| has |
| have |
| i |
| if |
| in |
| is |
| it |
| me |
| my |
| no |
| not |
| of |
| on |
| one |
| or |
| so |
| that |
| the |
| them |
| there |
| they |
| this |
| to |
| was |
| we |
| what |
| which |
| will |
| with |
| would |
| you |
| а |
| будем |
| будет |
| будете |
| будешь |
| буду |
| будут |
| будучи |
| будь |
| будьте |
| бы |
| был |
| была |
| были |
| было |
| быть |
| в |
| вам |
| вами |
| вас |
| весь |
| во |
| вот |
| все |
| всё |
| всего |
| всей |
| всем |
| всём |
| всеми |
| всему |
| всех |
| всею |
| всея |
| всю |
| вся |
| вы |
| да |
| для |
| до |
| его |
| едим |
| едят |
| ее |
| её |
| ей |
| ел |
| ела |
| ем |
| ему |
| емъ |
| если |
| ест |
| есть |
| ешь |
| еще |
| ещё |
| ею |
| же |
| за |
| и |
| из |
| или |
| им |
| ими |
| имъ |
| их |
| к |
| как |
| кем |
| ко |
| когда |
| кого |
| ком |
| кому |
| комья |
| которая |
| которого |
| которое |
| которой |
| котором |
| которому |
| которою |
| которую |
| которые |
| который |
| которым |
| которыми |
| которых |
| кто |
| меня |
| мне |
| мной |
| мною |
| мог |
| моги |
| могите |
| могла |
| могли |
| могло |
| могу |
| могут |
| мое |
| моё |
| моего |
| моей |
| моем |
| моём |
| моему |
| моею |
| можем |
| может |
| можете |
| можешь |
| мои |
| мой |
| моим |
| моими |
| моих |
| мочь |
| мою |
| моя |
| мы |
| на |
| нам |
| нами |
| нас |
| наса |
| наш |
| наша |
| наше |
| нашего |
| нашей |
| нашем |
| нашему |
| нашею |
| наши |
| нашим |
| нашими |
| наших |
| нашу |
| не |
| него |
| нее |
| неё |
| ней |
| нем |
| нём |
| нему |
| нет |
| нею |
| ним |
| ними |
| них |
| но |
| о |
| об |
| один |
| одна |
| одни |
| одним |
| одними |
| одних |
| одно |
| одного |
| одной |
| одном |
| одному |
| одною |
| одну |
| он |
| она |
| оне |
| они |
| оно |
| от |
| по |
| при |
| с |
| сам |
| сама |
| сами |
| самим |
| самими |
| самих |
| само |
| самого |
| самом |
| самому |
| саму |
| свое |
| своё |
| своего |
| своей |
| своем |
| своём |
| своему |
| своею |
| свои |
| свой |
| своим |
| своими |
| своих |
| свою |
| своя |
| себе |
| себя |
| собой |
| собою |
| та |
| так |
| такая |
| такие |
| таким |
| такими |
| таких |
| такого |
| такое |
| такой |
| таком |
| такому |
| такою |
| такую |
| те |
| тебе |
| тебя |
| тем |
| теми |
| тех |
| то |
| тобой |
| тобою |
| того |
| той |
| только |
| том |
| томах |
| тому |
| тот |
| тою |
| ту |
| ты |
| у |
| уже |
| чего |
| чем |
| чём |
| чему |
| что |
| чтобы |
| эта |
| эти |
| этим |
| этими |
| этих |
| это |
| этого |
| этой |
| этом |
| этому |
| этот |
| этою |
| эту |
| я |
| мені |
| наші |
| нашої |
| нашій |
| нашою |
| нашім |
| ті |
| тієї |
| тією |
| тії |
| теє |
Список не претендует на полную точность и вполне вероятно, что существуют еще какие-то стоп-слова. Учитывая, что у Яндекса есть турецкий поиск, то должны быть специфичные для этого языка стоп-слова.
Немного интересных и необъяснимых аномалий:
- В список стоп-слов Яндекс.Директа входит слово «наса» (предполагаю, что это что-то вроде склонения слова «нас»).
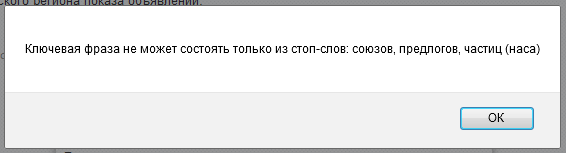
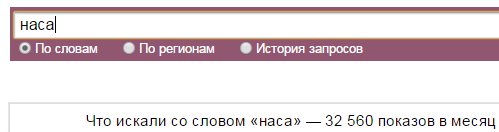
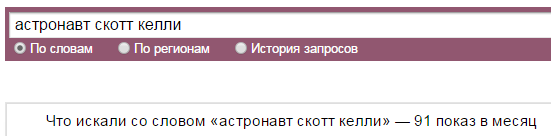
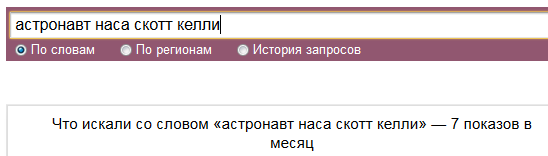
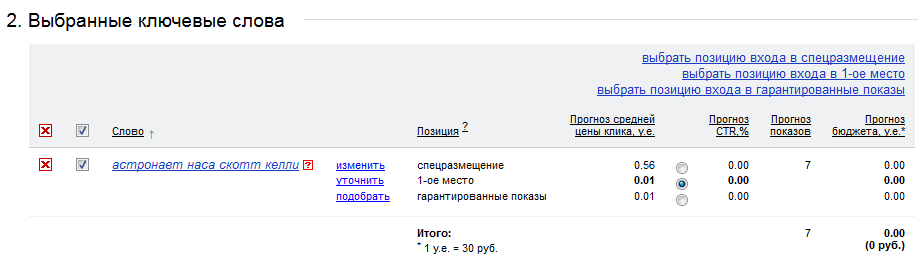
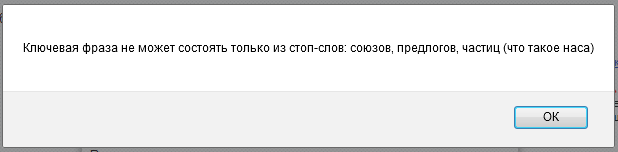
- Есть странные стоп-слова: «оне», «емъ», «комья», «томах», «имъ».
Но судя по разнице в количестве показов это всё стоп-слова только для валидатора сервиса прогноза бюджета:


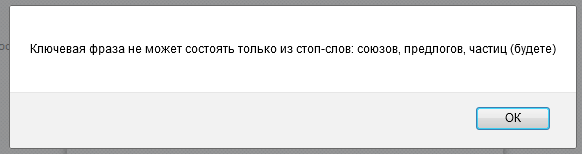
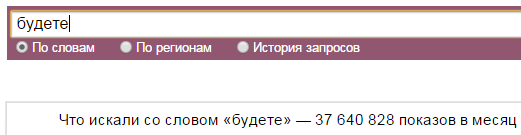
- Есть некоторые слова, которые в Вордстате имеют количество показов больше 0, но прогноз бюджета Яндекс.Директа говорит о том, что слово является стоп-словом. Например, слово «будете» — это стоп-слово для сервиса прогноза бюджета:


| будете |
| будучи |
| едим |
| едят |
| ел |
| ела |
| ем |
| емъ |
| ест |
| ешь |
| имъ |
| комья |
| наса |
| оне |
| сама |
| сами |
| самим |
| самими |
| самих |
| само |
| самого |
| самом |
| самому |
| саму |
| томах |
| тою |
| этою |
| am |
| could |
| me |
| them |
| мені |
| наші |
| нашої |
| нашій |
| нашою |
| нашім |
| ті |
| тієї |
| тією |
| тії |
| теє |
Фактически, эти слова учитываются при показе объявлений и стоп-словами не являются. Я включил их в список стоп-слов, так как завязывался на получение данных из API Яндекс.Директа с помощью метода CreateNewForecast. Этот метод не позволяет создать новый расчет если фраза состоит только из стоп-слов, поэтому мне нужно было точно знать список стоп-слов, которые не принимает метод. Использовать ли полный список или список без этих слов-аномалий — это зависит от решаемой задачи.
UPD: Благодаря Татьяне Михальченко и Олегу Саламаха список пополнился украинскими стоп-словами.
Вступайте в группу на Facebook и подписывайтесь на мой канал в Telegram, там публикуются интересные статьи про анализ данных и не только.
Объёмный получился список. Спасибо! Рынку пригодятся ;)
Благодарю за столь подробное рассмотрение темы, очень полезная информация, странно что так мало комментариев:-)
Большое спасибо за результаты исследования!
Благодарю
Спасибо за полезную работу и идеи!
Автору Памятник!
Так разобраться с Его Святейшеством, Непогрешимейшим и Непредсказуемейшим Яшей..... однозначно Памятник, хотя бы нерукотворный!
Спасибо Большое!!!
Благодарю Вас за проделанную работу!
Очень полезная инфа, спасибо за труд! + 10 к карме.
Респект и Большие человеческие сяпки!
Огромное спасибо. Самое то для лингвостатистических исследований
Огромнейшее спасибо за труд автору статьи! Очень полезно! Дай Бог Вам здоровья!
Спасибо за хорошую работу и пользу людям! Удачи!)
Спасибо большое!
«Благодаря Татьяне Михальченко и Олегу Саламаха список пополнился украинскими стоп-словами.» Мужские фамилии в русском языке СКЛОНЯЮТСЯ! Поэтому нужно писать «...и Олегу Саламахе...»
Да уж. Загадочный яндекс.
А вот этот список стоп-слов значит неполный?
https://yandex.ru/support/direct/keywords/keywords.html?lang=ru