To-do: Надо что-то сделать с пафосным названием статьи
Если вас интересует использование Logs API Яндекс.Метрики, то рекомендую сначала ознакомиться с текущей статьей, а затем прочитать статью «Становясь падаваном Logs API Яндекс.Метрики».
1. Лирическое отступление
Давно вынашивал идею написать что-то основательное про API Метрики. Взяться за дело меня вдохновила эта статья на хабре, посвященная выгрузке данных с помощью API Яндекс.Метрики. Но в ней, на мой взгляд, все сложновато, зачем создавать инстансы в Amazon, чтобы писать Python-скрипты? Достаточно поставить IPython и будет интерактивное счастье прямо в браузере, с блэкджеком и скаттер-плотами (для тех кто понимает о чем я). Но о том как использовать API Метрики с помощью IPython я напишу когда-нибудь потом, а в этой статье я хотел бы рассказать о том как научиться работать с API и получать данные Метрики в формате CSV с помощью одного запроса через браузер. Один раз скопировать запрос и никакой интерфейс Метрики больше не нужен.
Просто перейдя по ссылке можно выгрузить нужные данные:
https://api-metrika.yandex.ru/stat/v1/data.csv?metrics=ym:s:visits,ym:s:pageviews&dimensions=ym:s:lastTrafficSource&date1=31daysAgo&date2=yesterday&limit=10000&offset=1&ids=2138128&oauth_token=05dd3dd84ff948fdae2bc4fb91f13e22bb1f289ceef0037
Но для начала надо научиться эту ссылку формировать.
С функционалом API Яндекс.Метрики я знаком достаточно давно — с момента выхода второй версии API, которая состоялась одновременно с выходом Метрики 2.0. До этого времени работал только с Google Analytics, так как Яндекс.Метрика в принципе не устраивала своим скудным на тот момент функционалом: я осознавал систему как счетчик веб-статистики, но проделать серьезную аналитическую работу в ней было сложно, разве что с помощью «Конструктора отчетов». Что я подразумеваю под «серьезной» аналитикой? Прежде всего, в моем понимании это построение отчетов с множеством параметров и показателей, а также возможность сегментировать данные по различным критериям. Гигантская проблема заключалась в том, что методы «Констуктора отчетов» не были доступны в первой версии API Метрики, а значит чтобы автоматизировать сбор нужных данных приходилось парсить веб-страницы Метрики, что, мягко говоря, не удобно. Выход нового API стал для компании, в которой я работаю, мощным толчком перейти с использования Google Analytics на Яндекс.Метрику в качестве основной системы веб-аналитики. Причин тут много:
- Широкая распространенность счетчиков Метрики в рунете
- Метрика продолжает показывать поисковые запросы, в отличие от Google Analytics
- Подробная статистика по кампаниям Яндекс.Директа с детализацией до поисковых запросов
- Как позже оказалось: дружелюбная и достаточно быстрая поддержка (которой я уже, наверно, надоел, но они продолжают героически отвечать)
Миграция с API GA на API Метрики оказалась весьма безболезненной, во многом благодаря тому, что разработчики обеспечили совместимость запросов к Google Analytics Core Reporting API, сделав отдельное совеместимое API. С Core Reporting я был «на ты», поэтому начать пользоваться совместимым API было проще простого.
Если кому интересно про работу с Google Analytics Core Reporting API, то можете ознакомиться с презентацией моего доклада на iMetrics. Чтобы окончательно добить эту тему, по мотивам доклада написал две статьи: первая и вторая. С тех пор интерфейс GA Query Explorer несколько изменился, но изменения больше косметические. Вообще, благодаря Query Explorer работать с API Google Analytics легко. Такого инструмента мне не хватает в Яндекс.Метрике.
Позже оказалось, что совместимое API не содержит всех доступных в Метрике параметров, к тому же в нем периодически попадались неприятные баги, поэтому было решено переходить на использование нативного API Яндекс.Метрики 2.0.
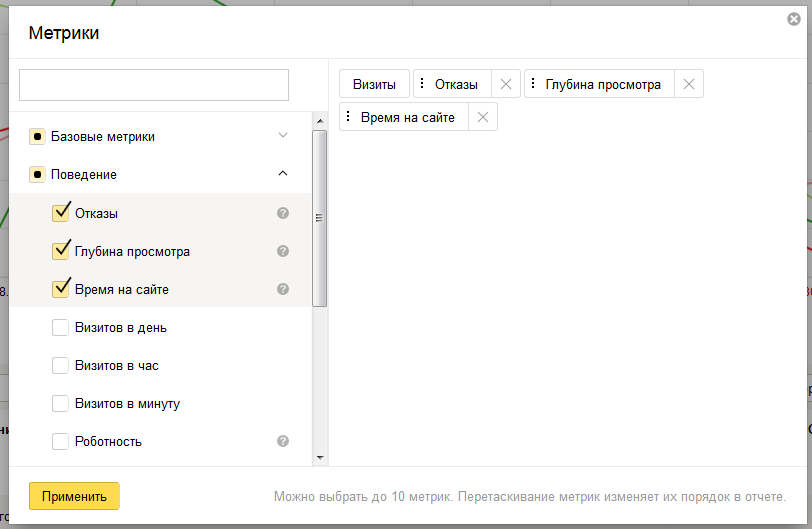
2. Группировки и метрики
Яндекс.Метрика (и её API) оперирует двумя основными сущностями: Dimensions (группировки) и Metrics (метрики). Эта терминология пришла из технологии обработки данных OLAP, она также встречается и в Google Analytics. Благодаря этому, API GA и API Метрики 2.0 очень похожи, и это существенный плюс, потому что начать работать с нативным API Метрики было очень легко, имея опыт работы с API GA.
Группировки/Dimensions (мне их привычнее называть «измерениями», но буду придерживаться терминологии Метрики) — это какой-либо атрибут визита или хита. Как ясно из названия, группировки позволяют группировать данные по определенным признакам.
Примеры группировок: Источник трафик, Город, Браузер, Страница входа.
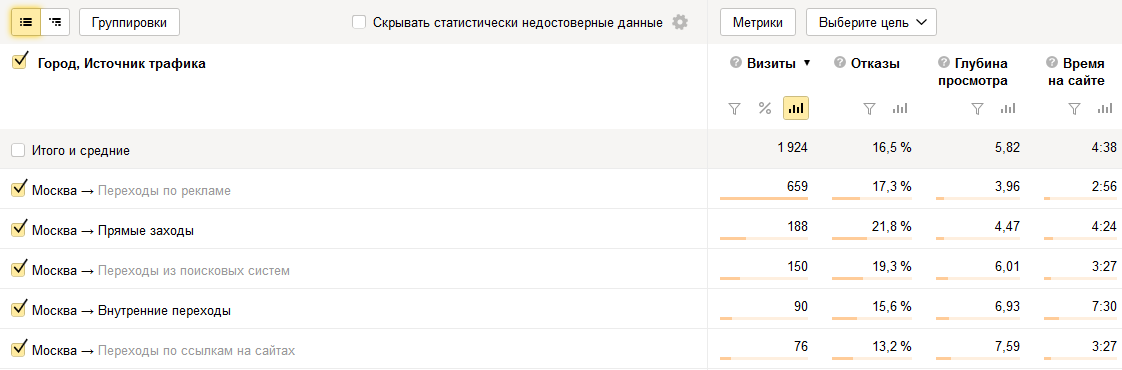
Группировки — это все те параметры, которые можно найти в одноименном разделе при построении отчета в интерфейсе Метрики:
Метрики/Metrics — это числовые величины, которые связаны с визитом или хитом.
Примеры метрик: количество визитов, показатель отказов, среднее время на сайте.
В интерфейсе метрики представлены в правой части табличных отчетов и их также список также можно настраивать:
3. Пример
Метрики и группировки взаимосвязаны. Чтобы понять эту взаимосвязь можно рассмотреть пример посетителя, совершающего посещение сайта.
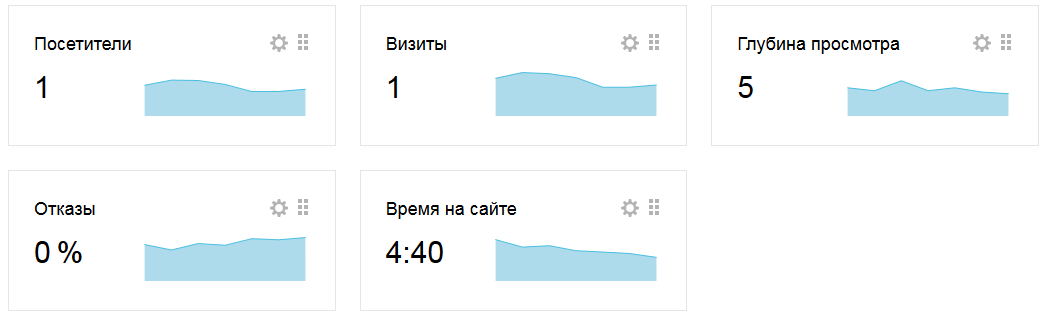
Пускай, это единственное посещение за всю историю сайта. Атрибуты посетителя, например, его город, браузер, источник трафик, пол, возвраст, все что удалось определить Яндекс.Метрике — это группировки. Яндекс.Метрика определила, что пользователь: пришел из Москвы, из поисковой системы Яндекс.
- Значение группировки «Город» для этого посещения будет «Москва»
- Значение группировки «Источник трафика» — «Переходы из поисковых систем»
В ходе посещения посетитель просматривает 5 страниц в течение 4 минут 40 секунд, тогда:
- Значение метрики «Просмотры» будет равно 5 страницам
- Значение метрики «Длительность визита» — 280 секунд
- Значение метрики «Отказы» будет равно 0%, т. к.
доля отказов для этого посещения будет равна 0%, т. к. пользователь просмотрел более одной страницы. Общая статистика посещений будет выглядеть так:
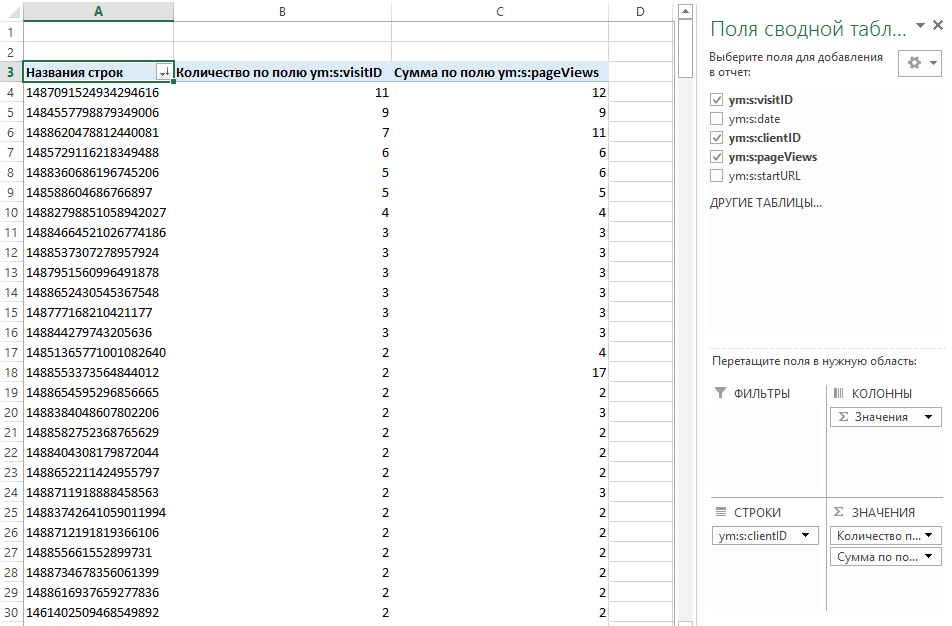
Общая статистика — это отчет, в котором отсутствуют группировки. Создав отчет с группировкой «Город» и метриками «Визиты» и «Просмотры» мы получим вот такой отчет:
Добавим группировку «Источник трафика» и отчет станет выглядеть вот так:
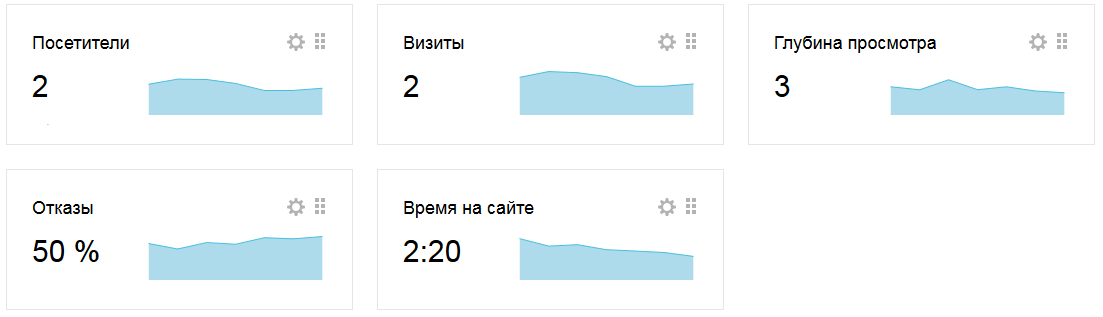
А теперь предположим, что пришел второй посетитель, тоже через ПС Яндекс, но из Петербурга. Он просмотрел за свой визит 1 страницу и был на сайте меньше 15 секунд. Такой визит будет считаться отказным, значит:
- Значение метрики «Просмотры» будет равно 1 странице
- Значение метрики «Длительность визита» — 0 секунд
- Значение метрики «Отказы» — 100%
Общая статистика посещений станет такой:
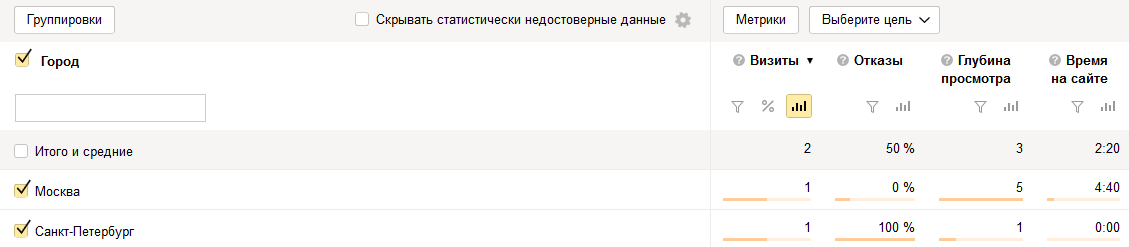
Если мы построим отчет с единственной группировкой «Источник трафика», то отчет будет иметь такие же значения метрик, как и в целом по сайту, т. к. у нас два посетителя, у которых одинаковое значение группировки «Источник трафика» — они оба пришли из поисковых систем, данные по ним сгруппировались:
Теперь изменим группировку отчета на «Город»:
Отчет принимает совершенно другой вид: у нас в нем появились две строки, несущие в себе два диаметрально противополжных факта. Отсюда вывод: правильные группировки помогают увидеть правильную информацию в правильном разрезе. Я считаю это основопологающим принципом веб-аналитики и аналитики данных вообще.
Надеюсь, этот пример дал понимание что такое группировки и метрики.
4. Получение доступа к API
Метрика использует протокол OAuth. Этот протокол позволяет работать с данными Яндекса от лица пользователя Яндекса через приложение, зарегистрированное на Яндексе. Приложение получает доступ к данным пользователя с помощью специального ключа, называемого токеном. Итак, прежде чем начать использовать API Яндекс.Метрики нам нужно создать приложение и получить от имени пользователя OAuth-токен, с помощью которого мы будем делать свои запросы к API.
1: Заходим на страницу https://oauth.yandex.ru/
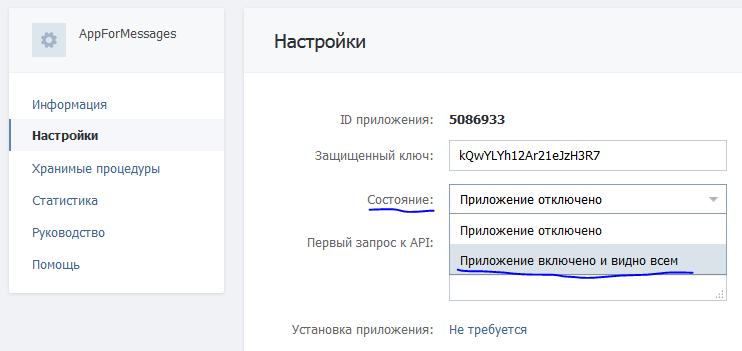
2: Нажимаем «Зарегистрировать новое приложение»
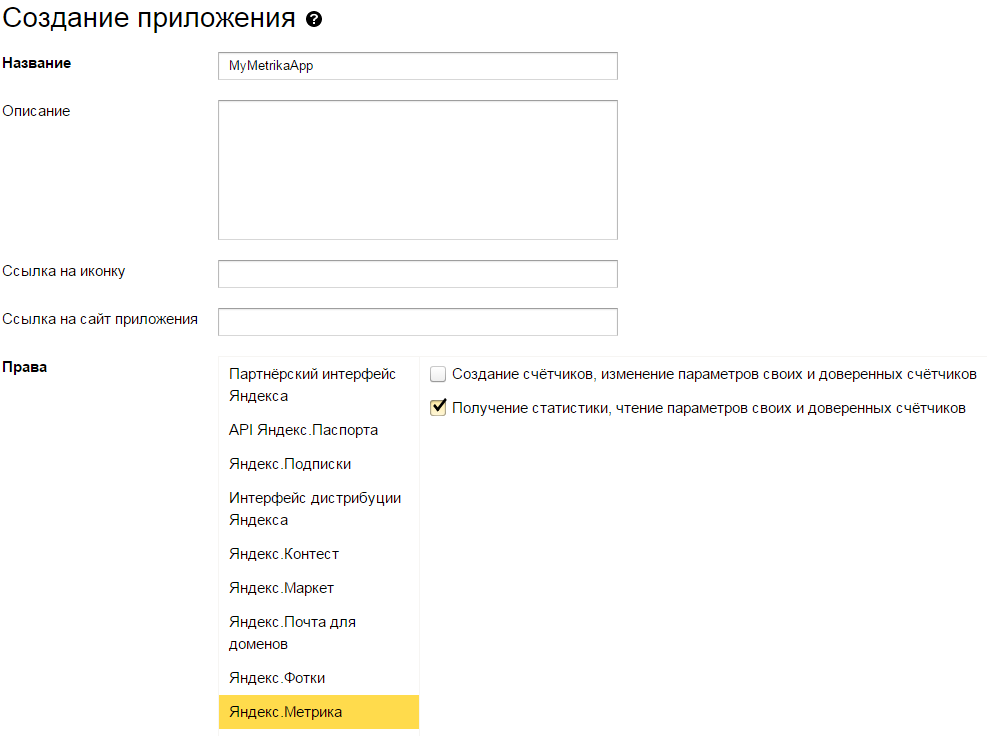
3: Запоняем поле «Название»
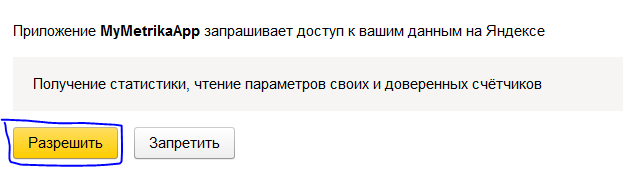
4: Выбираем в разделе права «Яндекс.Метрика» и ставим галочку напротив пункта «Получение статистики, чтение параметров своих и доверенных счетчиков»
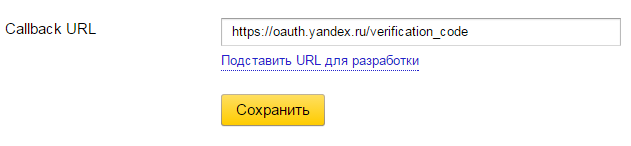
5: Нажимаем на ссылку «Подставить URL для разработки» под полем «Callback URL»
6: Нажимаем «Сохранить»
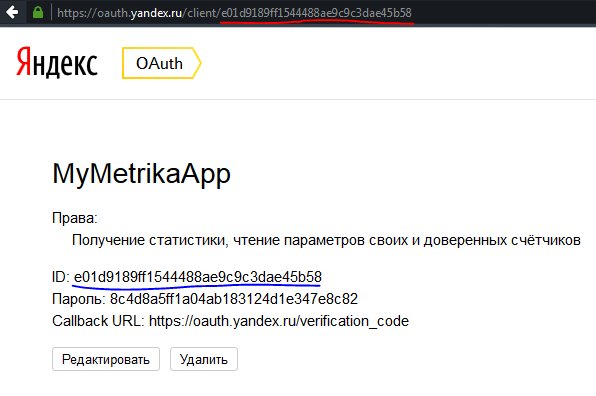
7: На открывшейся странице копируем ID приложения (его также можно скопировать увидеть в URL страницы)
8: Авторизуемся на Яндексе под учеткой пользователя, от имени которого будет работать приложение. (
Вы можете получать данные с разных логинов Яндекс.Метрики используя одно и то же приложение, только для этого нужно сначала выдать каждому логину свой токен доступа.)
9: Переходим по URL:
https://oauth.yandex.ru/authorize?response_type=token&client_id=<идентификатор приложения> (В моем случае URL будет такой:
https://oauth.yandex.ru/authorize?response_type=token&client_id=e01d9189ff1544488ae9c9c3dae45b58 и этот URL будет действителен и для вас, и токен вы получите, но лучше создайте свое приложение и укажите свой id)
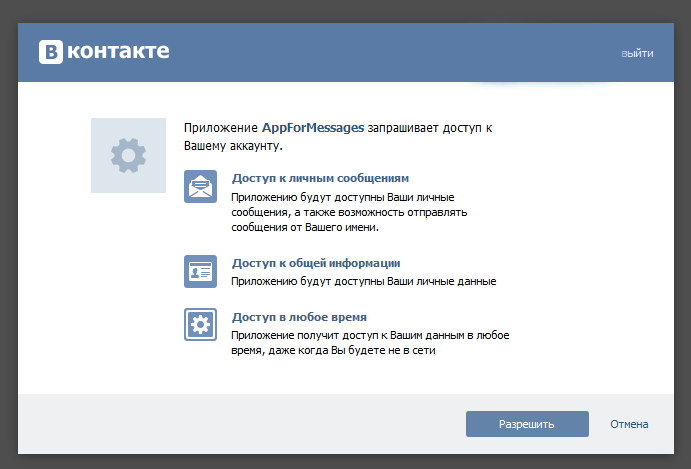
10: Приложение запросит разрешение на доступ, которое нужно предоставить, нажав «Разрешить»:
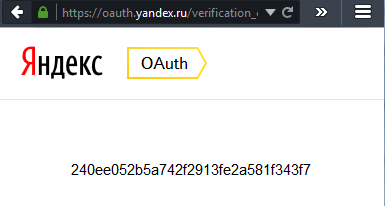
11: После чего мы получим токен:
Скопируйте и сохраните его. Этот токен позволит получать данные Яндекс.Метрики для счетчиков того логина, которому вы выдали разрешение на доступ. Срок действия токена большой, если честно даже не знаю насколько большой. Для другого логина нужен будет другой токен, его легко получить перейдя по https://oauth.yandex.ru/authorize?response_type=token&client_id=<идентификатор приложения>. Если приложению уже предоставлен доступ, то повторно перейдя по адресу мы снова получим тот же токен, что был выдан ранее.
Открывать доступ к собственноручно созданному приложению — это безопасно, в случае с открытием доступов к стороннему приложению, рекомендую смотреть на уровень доступа к данным. Например, у сторонних приложений, которые строят отчеты по API на основе данных Яндекс.Метрики, не должно быть доступов к редактированию счетчиков. На странице «Управление доступом» в Яндекс.Паспорте можно увидеть каким приложением предоставлен доступ к данным Метрики.
5. Структура запроса к API
Итак, у нас есть токен и теперь мы можем делать запрос. В качестве примера токена я буду использовать тестовый токен, указанный в документации Яндекс.Метрики:
05dd3dd84ff948fdae2bc4fb91f13e22bb1f289ceef0037
В API Метрики есть несколько типов запросов:
- Таблица
- Drill down
- Получение данных по времени
- Сравнение сегментов
- Сравнение — drill down
В этой статье я буду рассматривать только запрос «Таблица», т. к. он позволяет в дальнейшем сформировать любые нужные представления данных.
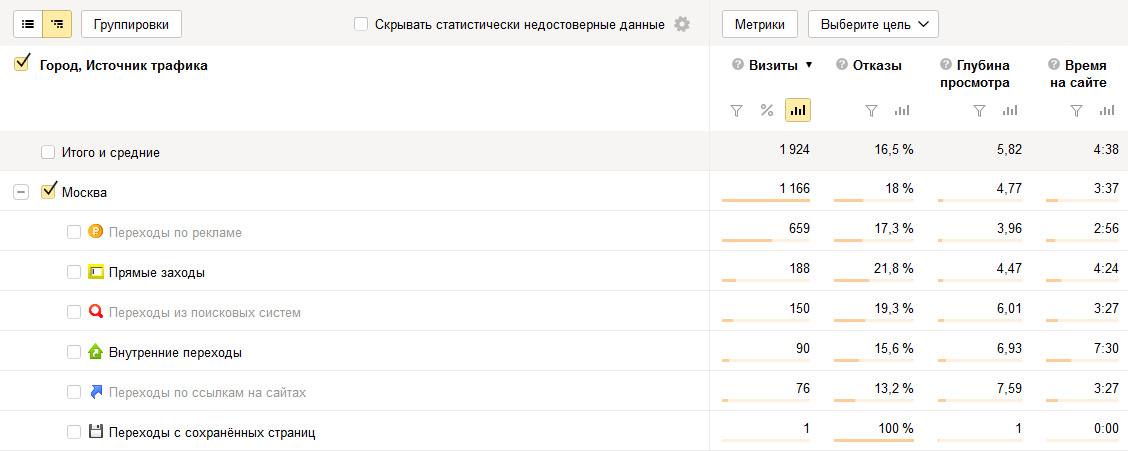
Запрос «Таблица» вытягивает «плоские» табличные данные, тогда как «Drill down» отдает иерархически вложенные друг в друга данные. Эта логика есть и в интерфейсе. Переключитесь между видом «Линейный список» и «Древовидный список»:
Вид «Древовидный список» удобен для анализа данных в интерфейсе: в поиске озарения можно углубляться и углубляться в данные до тех пор пока не кончатся группировки. Вид «линейный список» удобнее для анализа с помощью табличных процессоров (например, Excel) или обработки с помощью SQL-запросов, в датафрейме R или Pandas. Когда группировок много, «плоский» вид данных несомненно выигрывает, так как позволяет быстро манипулировать всеми доступными данными, а иерархический список жестко привязывает нас к заданной иерархии вложенности группировок.
Запрос к API Метрики — это обычный GET-запрос, который можно выполнить из браузера. Этот запрос представляет собой основной URL «https://api-metrika.yandex.ru/stat/v1/data», вопросительный знак «?» и дальше идут параметры запроса, которые перечисляются через знак «&». Параметров запроса много, но я коснусь только основных. Упрощенно структура запроса выглядит так:
https://api-metrika.yandex.ru/stat/v1/data ?
metrics=<string>
& dimensions=<string>
& date1=<string>
& date2=<string>
& limit=<integer>
& offset=<integer>
& ids=<int,int,...>
& oauth_token=<string>
В одну строку это выглядит так: https://api-metrika.yandex.ru/stat/v1/data?metrics=<string>&dimensions=<string>&date1=<string>&date2=<string>&limit=<integer>&offset=<integer>&ids=<int,int,...>&oauth_token=<string>
Обязательными параметрами являются только metrics, oauth_token и ids.
6. Формируем запрос к API
Начнем составление нашего запроса к API
1 — В параметре metrics нужно перечислить список метрик. Они разделяются через запятую. Наименования метрик чувствительны к регистру. Максимальное число метрик в запросе — 20. Со списком метрик уровня визитов можно ознакомиться по ссылке. Чаще всего в отчетах нужны именно эти метрики, поэтому метрики уровня хита (просмотра) я в этой статье рассматривать не буду. Основные из метрик:
- ym:s:visits — количество визитов
- ym:s:pageviews — суммарное количество просмотров страниц
- ym:s:users — количество уникальных посетителей (за отчетный период)
- ym:s:bounceRate — показатель отказов
- ym:s:pageDepth — глубина просмотра
- ym:s:avgVisitDurationSeconds — средняя продолжительность визитов в секундах
- ym:s:goal<goal_id>reaches — количество достижений цели, где вместо надо подставить идентификатор цели (зайдите в настройки целей для конкретного счетчика, чтобы получить список их идентификаторов)
- ym:s:sumGoalReachesAny — суммарное количество достижений всех целей
Для тестового запроса выберем метрики «Визиты» (ym:s:visits) и «Просмотры» (ym:s:pageviews):
metrics=ym:s:visits,ym:s:pageviews
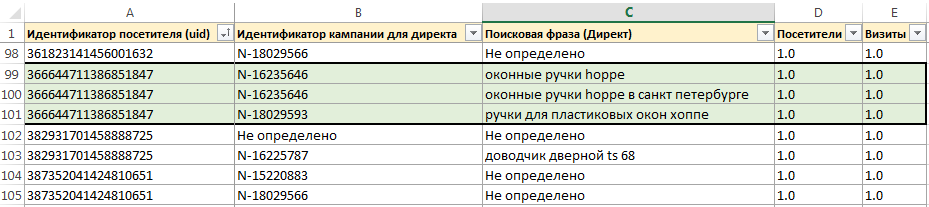
2 — В параметре dimensions нужно перечислить список группировок. Группировки — это необязательный параметр и если их не задать, то в отчете будет представлена общая статистика по сайту. Они также как и метрики разделяются запятой, тоже чувствительны к регистру. Максимальное их число — 10 в одном запросе. Со списком группировок уровня визитов можно ознакомиться по ссылке. Группировки более разнообразны чем метрики. Лично я чаще всего сталкиваюсь с тем, что набор метрик в запросе всегда неизменен, а вот группировки применяю самые различные, в зависимости от стоящей задачи. Поэтому я бы порекомендовал подробно ознакомиться со списком доступных группировок.
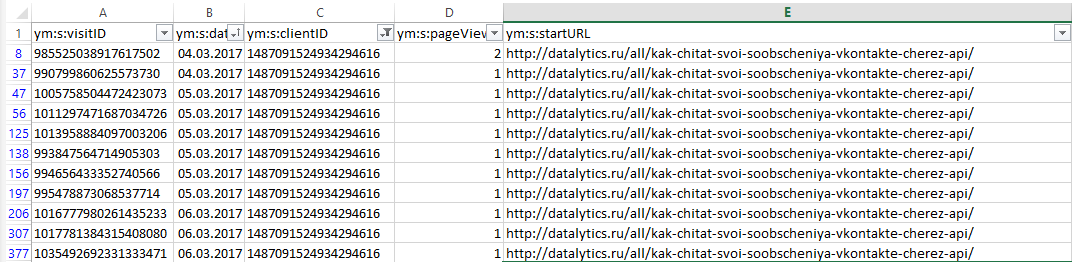
Вот пример того какие группировки нужны, чтобы построить отчет по поисковым системам с детализацией до запросов и посадочных страниц:
- ym:s:<attribution>SearchEngine> — поисковая система
- ym:s:<attribution>SearchPhrase> — поисковый запрос
- ym:s:startURL — посадочная страница
Для группировки по датам можно добавить параметр ym:s:date.
Мы видим в группировках параметр <attribution>. В некоторых группировках нужно задать атрибуцию трафика. Она определяет как сессии пользователей будут привязываться к источнику трафика. Например, если мы поставили атрибуцию по последнему источнику, то к конкретному источнику в отчете будут отнесены сессии посетителей, у которых этот источник был последним. Существует несколько типов атрибуции трафика:
- first — атрибуция по первому источнику
- last — атрибуция по последнему источнику
- prev — атрибуция по предыдущему источнику
- lastSign — атрибуция по последнему значимому источнику (значимым считается любой источник, отличный от прямых и внутренних переходов).
Атрибуция в группировках задается с помощью параметризации и тут существует два способа:
- Подставить вместо <attribution> один из типов (first, last или lastSign) (например, ...&dimensions = ym:s:lastSignSearchEngine&...)
- Оставить <attribution> в группировке и добавить в запрос параметр attribution (например ...&dimensions = ym:s:<attribution>SearchEngine&attribution=lastSign...)
Для тестового запроса выберем группировку «Источник трафика» (ym:s:referer):
dimensions=ym:s:referer
О чем еще важно знать:
- Существует разделение области действия группировок и метрик на «визиты» и «хиты». Это разделение важно учитывать во внимание при запросах к API, нельзя использовать вместе измерения или метрики, которые относятся к разным областям применения. Группировки и метрики, начинающиеся с «ym:s:», имеют область действия «визиты» (s — session), а группировки и метрики, начинающиеся с «ym:pv:» относятся к «хитам» (pv — pageview — просмотр страницы).
- Есть группировки, которые могут принимать в определенных случаях пустое значение (null). Например, группировка «поисковая фраза» будет принимать какое-то значение только, когда есть информация о поисковой фразе. Ясно, что если переход был, к примеру, из социальной сети, то поискового запроса там и в помине не будет. Поэтому если группировка стоит первой в перечне, то при получении статистики из API Метрики будут отображены только те данные, где группировка не принимает пустое значение.
3 — date1 — дата начала отчетного периода в формате YYYY-MM-DD (например, 2015-08-31). Кроме абсолютных значений в формате YYYY-MM-DD можно задавать относительные значения:
- today — сегодняшняя дата
- yesterday — вчерашняя дата
- ndaysAgo — n дней назад от сегодняшней даты, где вместо n надо указать количество дней, например 30daysAgo.
Если не задать начальную дату, то применится значение по умолчанию — 6daysAgo (6 дней назад от текущей даты).
Поставим в качестве даты начала отчета 1 января 2015 года:
date1=2015-01-01
4 — date2 — дата окончания отчетного периода в формате YYYY-MM-DD. Формат такой же как у date1. Важно, чтобы date2 не была меньше date1, а так date2 может быть даже в будущем, запрос будет работать.
Конечная дата date2 в нашем отчете будет вчерашним днем:
date2=yesterday
5 — параметр limit — ограничение на количество возвращаемых результатов. По умолчанию — 100, но максимум — 10000. Я чаще всего во всех запросах использую limit=10000, этого хватает для большинства запросов, но бывает, что отчет возвращает больше строк и тогда нам поможет следующий параметр.
В нашем запросе будем получать максимум — 10000 строк:
limit=10000
6 — параметр offset определяет первую строку выборки, значение по умолчанию — 1, что означает, что отчет будет генерироваться с первой строки. Этот параметр полезен, когда отчет содержит больше чем 10000 строк. Предположим, у нас больше 10000 строк. Первым запросом с offset=1 и limit=10000 мы выгрузим первые 10000 строк. Установив offset=10001 мы выгрузим данные, начиная с 10001 строки, при limit=10000 это означает, что будут выгружены строки 10001-20000. Если данных больше, чем 20000, то нужно сделать третий запрос, увеличив offset еще на 10000. И так далее в зависимости от объемов данных.
Устанавливаем первую строку:
offset=1
7 — ids содержит перечень идентификаторов счетчиков. Это поле поддерживает более одного значения, это значит мы можем одним запросом выгружать данные с нескольких счетчиков.
Для нашего тестового запроса возьмем значения ids=2138128,2215573.
Важно помнить, что если мы включаем в отчет данные более чем 1 счетчика, то они будут сгруппированы по тем группировкам, которые мы задали в dimensions. Это означает, что для того, чтобы разделить данные на отдельные сайты нужно передать в отчет какой-то параметр, который будет точно идентифицировать каждый из сайтов, например, добавить группировку «Домен страницы входа» (ym:s:startURLDomain).
Тогда полный список наших группировок будет таким:
dimensions=ym:s:referer,ym:s:startURLDomain
8 — параметр oauth_token — это авторизационный токен. Для каждого пользователя (логина Метрики) должен быть свой токен. Если запросить данные по счетчикам, воспользовавшись другим токеном, не подходящим к пользователю, то запрос возвратит сообщение об ошибке.
Мы будем использовать тестовый токен, указанный в документации:
oauth_token=05dd3dd84ff948fdae2bc4fb91f13e22bb1f289ceef0037
Итак, мы собрали наш запрос по кусочкам и вот что получили:
https://api-metrika.yandex.ru/stat/v1/data?metrics=ym:s:visits,ym:s:pageviews&dimensions=ym:s:referer,ym:s:startURLDomain&date1=2015-01-01&date2=yesterday&limit=10000&offset=1&ids=2138128,2215573&oauth_token=05dd3dd84ff948fdae2bc4fb91f13e22bb1f289ceef0037
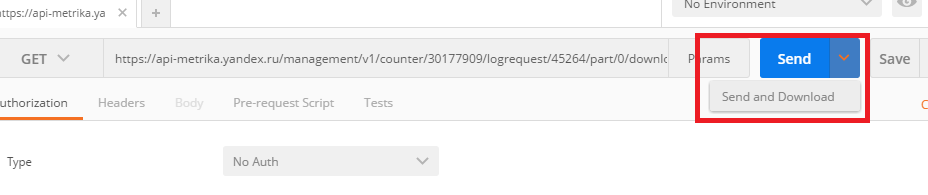
7. Выполняем запрос
Теперь вставим запрос в адресную строку браузера и выполним его, перейдя по URL (ну или просто перейдите по ссылке выше).
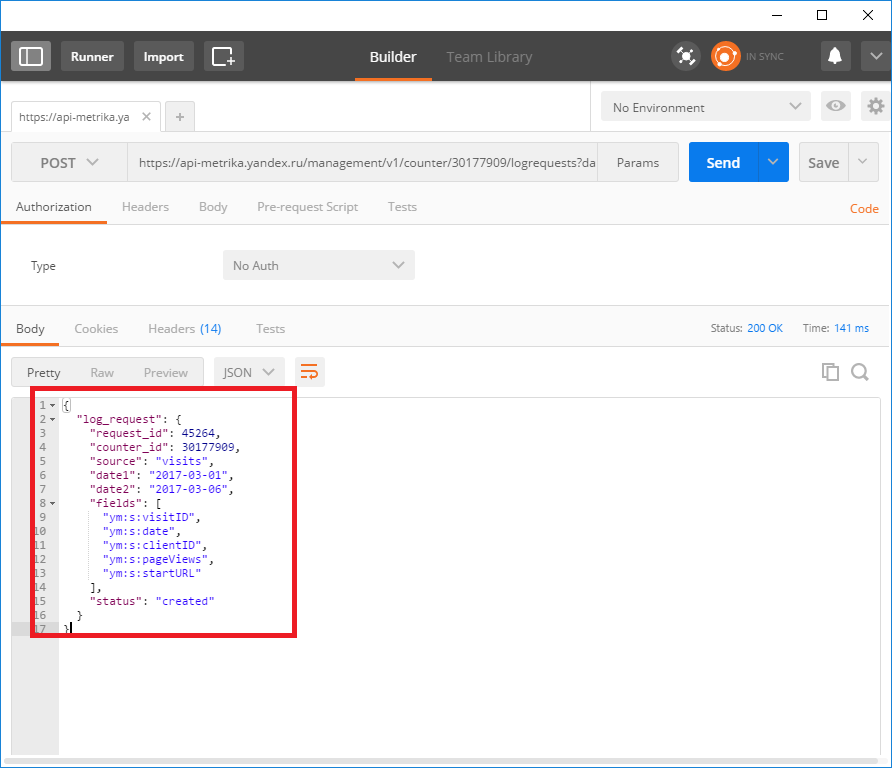
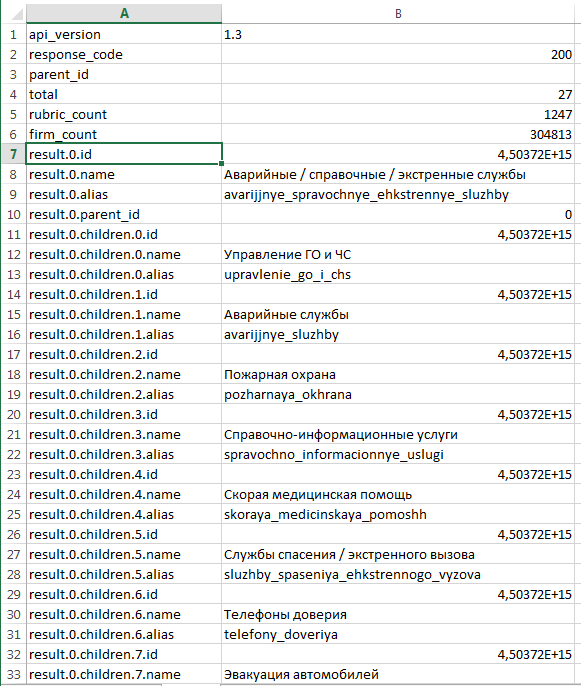
Получили вот такой ответ:
Не стоит пугаться, это ответ в формате JSON. На самом деле, это крайне удобный формат данных, но пригоден он для использования в программировании, формировании post-запросов на веб-сервера, а вот человеку не очень просто быстро в нем разобраться. Чтобы облегчить эту задачу сделаем JSON более «красивым», добавив к запросу параметр pretty=true:
https://api-metrika.yandex.ru/stat/v1/data?metrics=ym:s:visits,ym:s:pageviews&dimensions=ym:s:referer,ym:s:startURLDomain&date1=2015-01-01&date2=yesterday&limit=10000&offset=1&ids=2138128,2215573&oauth_token=05dd3dd84ff948fdae2bc4fb91f13e22bb1f289ceef0037&pretty=true
Теперь стало чуть более понятно:
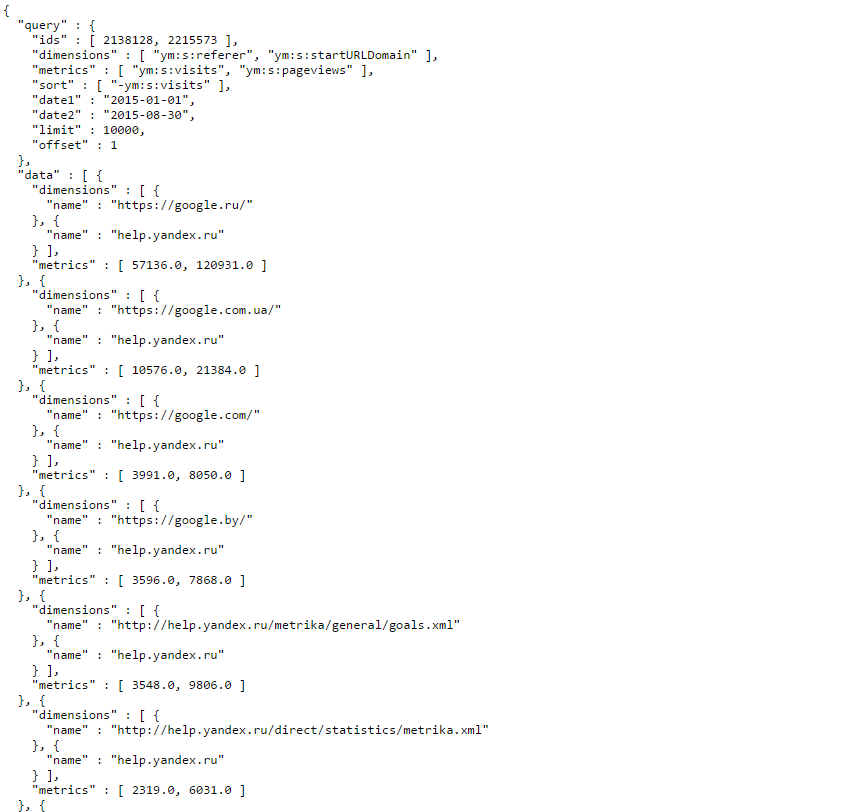
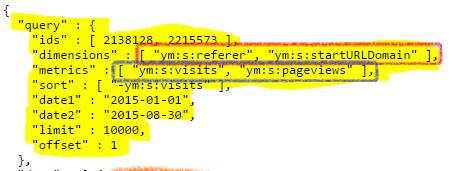
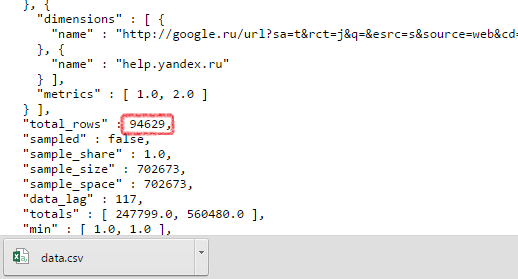
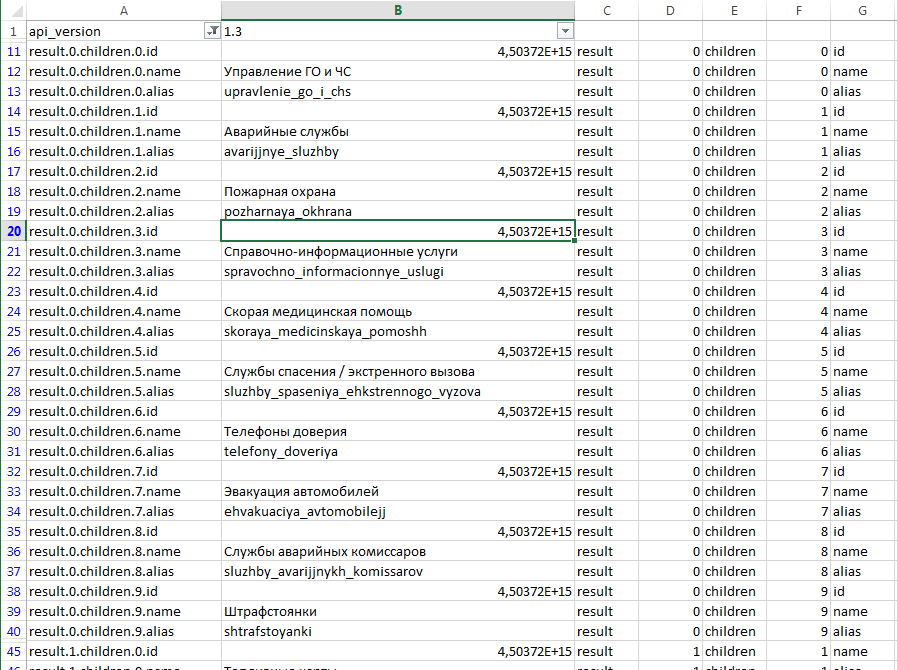
Верхушка ответа от API — это параметры нашего запроса (выделена желтым). Тут стоит обратить внимание на параметр dimensions. Это те группировки, что мы указали в своем запросе (выделены красной рамкой). А ниже metrics (выделены синей рамкой):
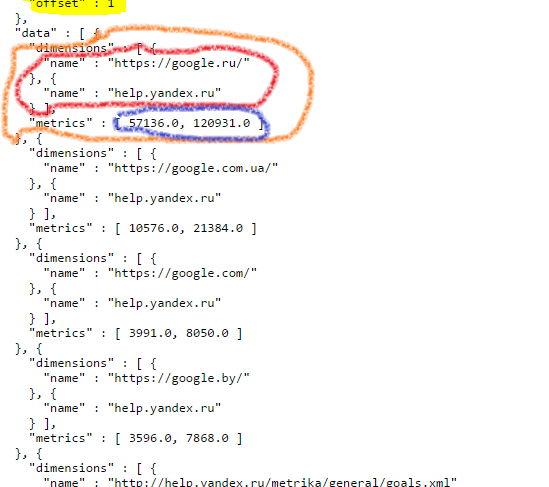
После перечисления параметров идет ответ от API. Ответ содержится в параметре data, он представлен в виде массива данных, заключенных в квадратные скобки. Этот массив — множество строчек данных, каждая из которых заключена в фигурные скобки. Я обвел один элемент массива оранжевой обводкой — это одна строка данных:
Внутри каждой строки есть dimensions (обведены красным) и metrics (обведены синим). Это значения наших группировок, они указаны в том порядке, в котором идут в параметрах запроса. Значит для этой строки данных:
- ym:s:referer=«https://google.ru/»
- ym:s:startURLDomain=«help.yandex.ru»
- ym:s:visits=57136.0
- ym:s:pageviews=120931.0
В интерфейсе Метрики эта строчка выглядела бы так:
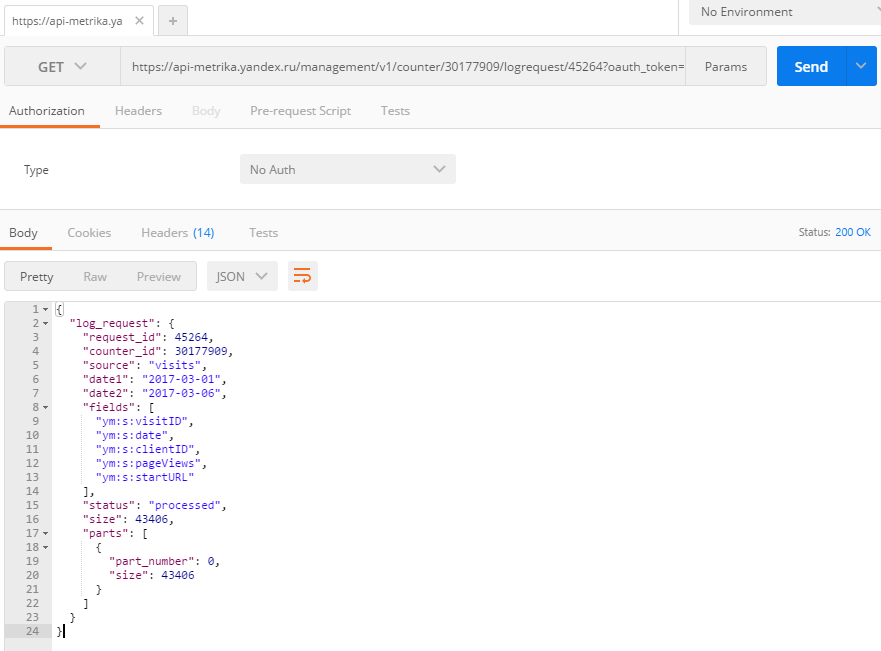
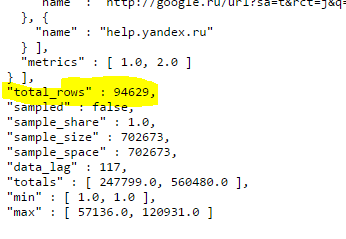
JSON, как я уже сказал, не самый человекопонятный вид данных, но только в JSON-формате API отдает важный параметр total_rows — общее количество строчек, доступных по заданному запросу. Чтобы найти этот параметр нужно перейти в самый конец страницы:
В нашем случае total_rows = 94629, а это значит, что нам пришлось бы сделать еще 9 запросов, итеративно увеличивая offset на 10000, чтобы выгрузить все данные.
Но оставим JSON разработчикам. Для «обывателей» (надеюсь никто не обидится) Метрика может отдавать данные в CSV. Всё, что для этого нужно — после data в запросе поставить параметр «.csv», тогда URL нашего запроса будет выглядеть так:
https://api-metrika.yandex.ru/stat/v1/data.csv?metrics=ym:s:visits,ym:s:pageviews&dimensions=ym:s:referer,ym:s:startURLDomain&date1=2015-01-01&date2=yesterday&limit=10000&offset=1&ids=2138128,2215573&oauth_token=05dd3dd84ff948fdae2bc4fb91f13e22bb1f289ceef0037 (обратите внимание, что я убрал pretty=true, т. к. для CSV-запроса он не нужен)
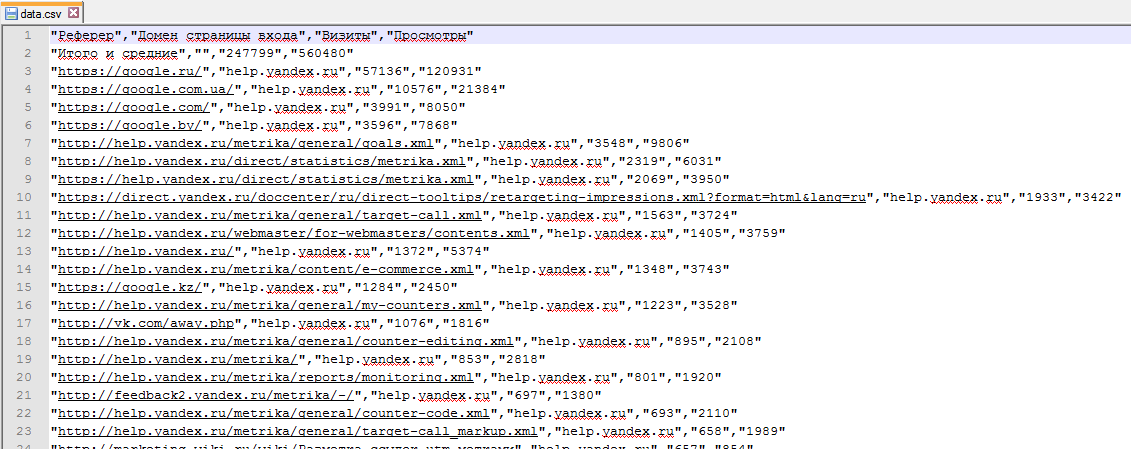
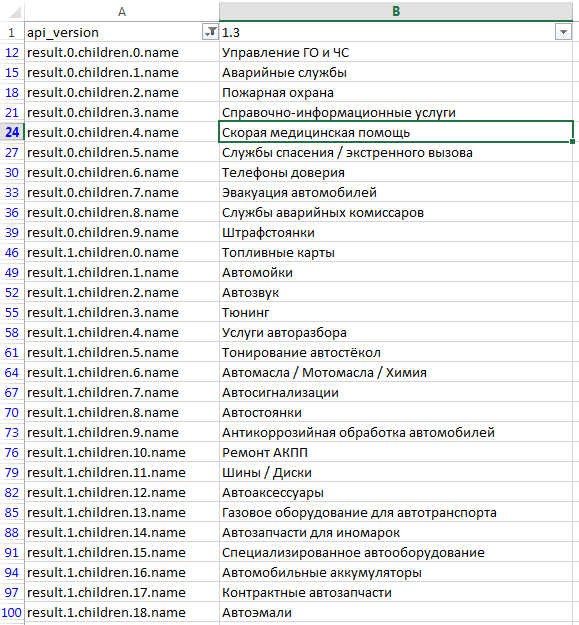
После того как мы сделаем запрос по этому URL, загрузится файл data.csv:
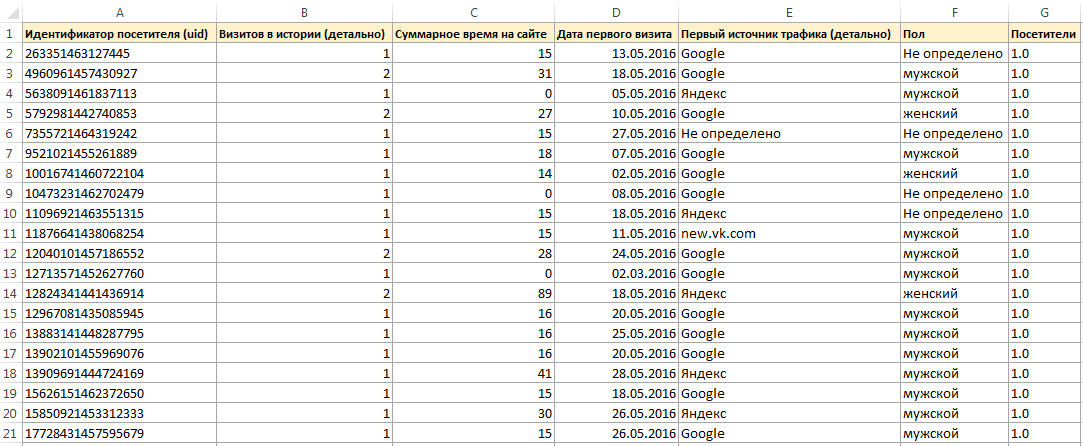
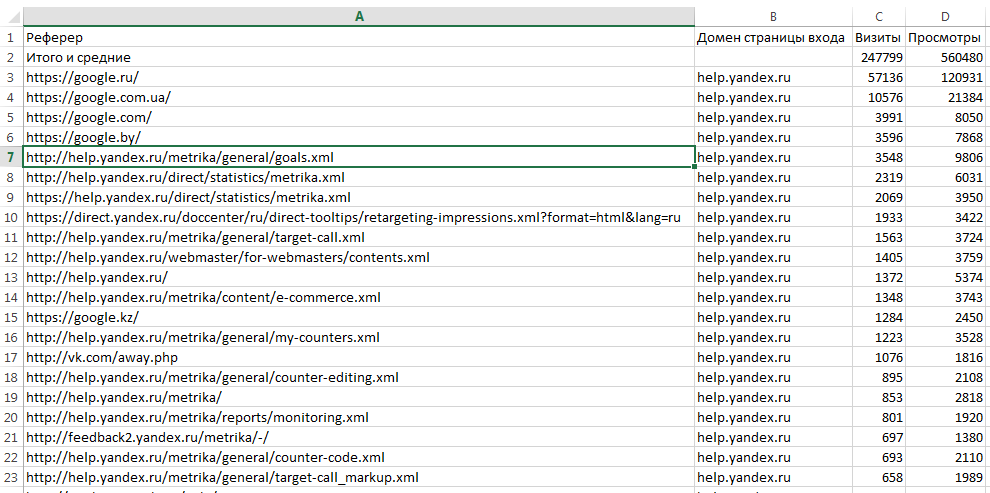
Загруженный CSV (Comma-separated values) представляет собой обычный текстовый файл в кодировке UTF-8, где значения разделены запятыми:
Перед нами наши данные в значительно более привычном виде. Сначала идет заголовок таблицы, тут уже нет никаких ym:s:referer и названия группировок и метрик отображаются также как и в интерфейсе. Затем идет строчка с итоговыми данными (по всей выборке, а не только по выгруженным 10000 строкам), а после идут строки с данными. Их 10000. Если мы хотим выгрузить остальное — надо делать ещё запросы (изменяя offset).
8. Импорт в Excel
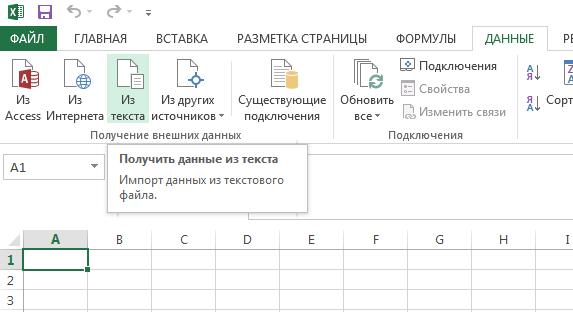
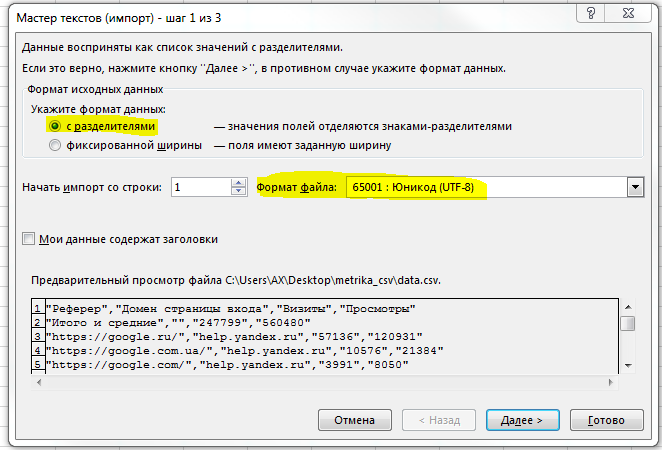
CSV очень просто загрузить в Excel, воспользовавшись функцией «Получение внешних данных из текста», которая находится в разделе «Данные»:
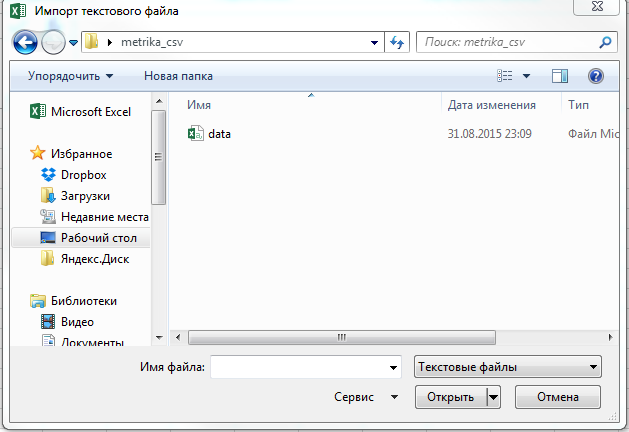
Сначала указываем путь к данным:
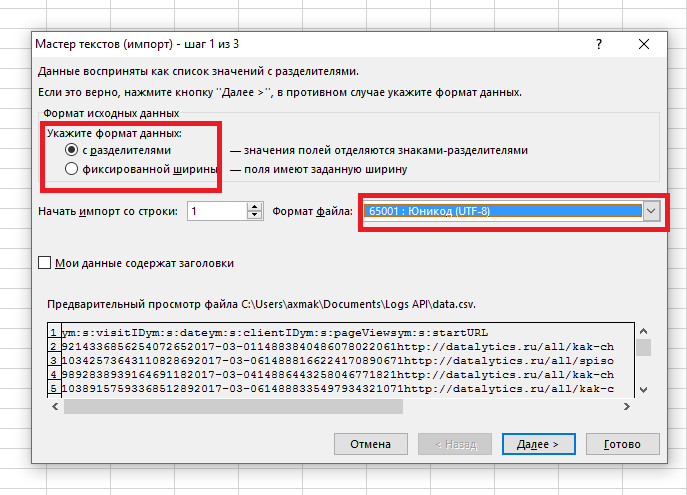
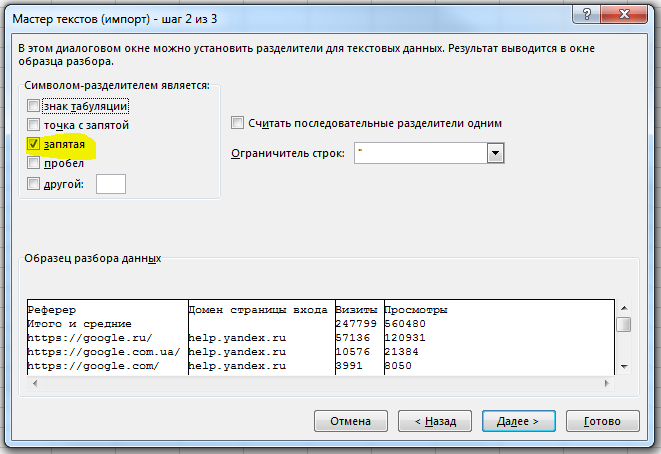
Указываем, что наши данные содержат разделители и задаем кодировку файла UTF-8:
Далее указываем используемый разделитель «запятая» и нажимаем «Готово»:
Помещаем данные на имеющийся или новый лист и вуаля:
9. Заключение
Таким образом, формирование нужных отчетов Яндекс.Метрики, которые будут в несколько кликов доступны для анализа, сводится к тому, чтобы:
а) сделать нужный URL запроса
б) запросить данные через браузер и скачать csv-файл
в) открыть csv-файл в Excel или любом другом табличном процессоре или приложении анализа данных
У запроса даже не нужно менять даты, потому что можно пользоваться такими параметрами: date1=7daysAgo&date2=yesterday. Такой запрос будет выбирать данные за последнюю неделю.
В качестве бонуса приведу некоторые сочетания группировок и метрик, которые могут пригодится. Идентификаторы счетчиков и токен невалидные, вам нужно будет поставить свои, чтобы запросы работали.
Отчет по Директу для поисковых кампаний
https://api-metrika.yandex.ru/stat/v1/data.csv?dimensions=ym:s:directSearchPhrase,ym:s:directClickOrder,ym:s:directBannerGroup,ym:s:directClickBanner,ym:s:directPhraseOrCond,ym:s:UTMSource,ym:s:UTMMedium,ym:s:UTMCampaign,ym:s:UTMContent&metrics=ym:s:visits,ym:s:pageviews,ym:s:bounceRate,ym:s:avgVisitDurationSeconds,ym:s:sumGoalReachesAny&filters=ym:s:directPlatformType=='search'&limit=10000&offset=1&ids=31458&oauth_token=53e1a43ac4af43be73e0ba2c4b&include_undefined=true
Отчет по Директу для кампаний РСЯ
https://api-metrika.yandex.ru/stat/v1/data.csv?dimensions=ym:s:directPlatform,ym:s:directClickOrder,ym:s:directBannerGroup,ym:s:directClickBanner,ym:s:directPhraseOrCond,ym:s:UTMSource,ym:s:UTMMedium,ym:s:UTMCampaign,ym:s:UTMContent&metrics=ym:s:visits,ym:s:pageviews,ym:s:bounceRate,ym:s:avgVisitDurationSeconds,ym:s:sumGoalReachesAny&filters=ym:s:directPlatformType=='context'&limit=10000&offset=1&ids=31458&oauth_token=53e1a43ac4af43be73e0ba2c4b&include_undefined=true
Отчет по ключевым словам из ПС с детализацией по целевым страницам (страницам входа) и статистикой поисковых запросов
https://api-metrika.yandex.ru/stat/v1/data.csv?dimensions=ym:s:lastSearchEngine,ym:s:lastSearchPhrase,ym:s:startURL&metrics=ym:s:visits,ym:s:pageviews,ym:s:bounceRate,ym:s:avgVisitDurationSeconds,ym:s:sumGoalReachesAny&filters=ym:s:lastTrafficSource=='organic'&limit=10000&offset=1&ids=31458&oauth_token=53e1a43ac4af43be73e0ba2c4b&include_undefined=true
(Используется атрибуция last)
Отчет по источникам трафика (каналам), детальным источникам трафика, реферерам и целевым страницам
https://api-metrika.yandex.ru/stat/v1/data.csv?dimensions=ym:s:lastTrafficSource,ym:s:lastSourceEngine,ym:s:referer,ym:s:startURL&metrics=ym:s:visits,ym:s:pageviews,ym:s:bounceRate,ym:s:avgVisitDurationSeconds,ym:s:sumGoalReachesAny&limit=10000&offset=1&ids=31458&oauth_token=53e1a43ac4af43be73e0ba2c4b&include_undefined=true
(Используется атрибуция last)
О чем еще важно помнить:
- В документации ей всё, ну или почти всё (есть кое-что, что не описано :). Например, есть полный список группировок и метрик
- Один запрос содержит не более 10 измерений, не более 20 метрик
- Не все группировки и метрики (одинаково полезны) совместимы (ym:s: и ym:pv:), также нельзя вместе применять некоторые группировки Директа с другими группировками (например, нельзя сделать группировку по часам или по городам, если есть группировка Директа)
- На одного пользователя (один логин) есть ограничение в 5000 запросов в день
Успехов в автоматизации! Она заставляет поверить, что в мире есть место «магии». А еще даёт возможность убить тупую рутину и больше времени посвящать размышлениям и творчеству :)
Вступайте в группу на Facebook и подписывайтесь на мой канал в Telegram, там публикуются интересные статьи про анализ данных и не только.





































{kind=link}